DB-GPT V0.7.0 Release: MCP Protocol Support, DeepSeek R1 Model Integration, Complete Architecture Upgrade, GraphRAG Retrieval Chain Enhancement, and More..
DB-GPT is an open-source AI Native Data App Development framework with AWEL and Agents. In version V0.7.0, we have reorganized the DB-GPT module packages, splitting the original modules, restructuring the entire framework configuration system, and providing a clearer, more flexible, and more extensible management and development capability for building AI native data applications around large models.
V0.7.0 version mainly adds and enhances the following core features
🍀 Support for MCP(Model Context Protocol) protocol.
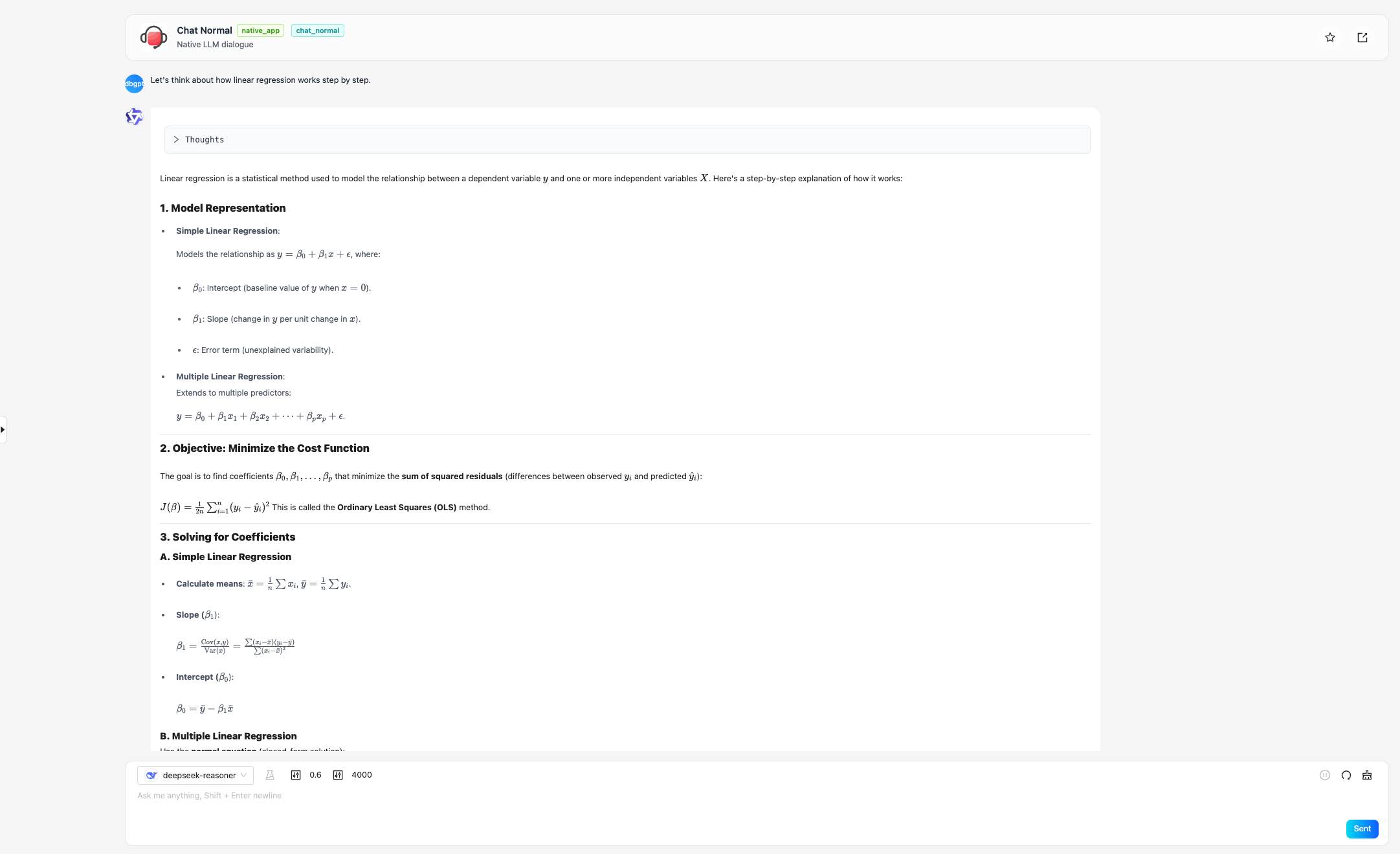
🍀 Integrated DeepSeek R1, QWQ inference models, all original DB-GPT Chat scenarios now cover deep thinking capabilities.
🍀 GraphRAG retrieval chain enhancement: support for "Vector" and "Intent Recognition+Text2GQL" graph retrievers.
🍀 DB-GPT module package restructuring, original dbgpt package split into dbgpt-core, dbgpt-ext, dbgpt-serve, dbgpt-client, dbgpt-acclerator, dbgpt-app.
🍀 Reconstructed DB-GPT configuration system, configuration files changed to ".toml" format, abolishing the original .env configuration logic.
1. Support for MCP(Model Context Protocol) protocol
Usage instructions:
a. Run the MCP SSE Server gateway:
npx -y supergateway --stdio "uvx mcp-server-fetch"
Here we are running the web scraping mcp-server-fetch
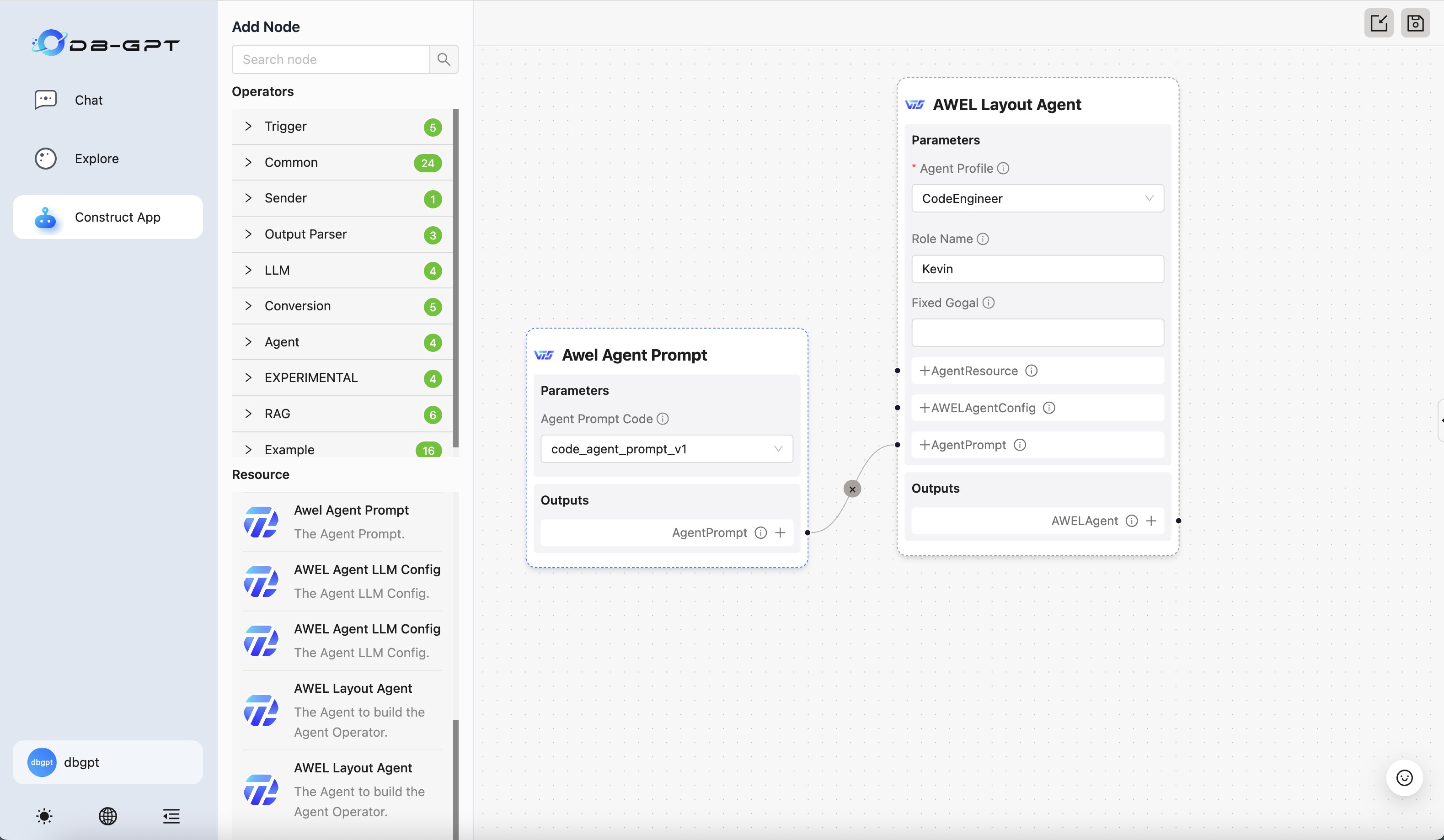
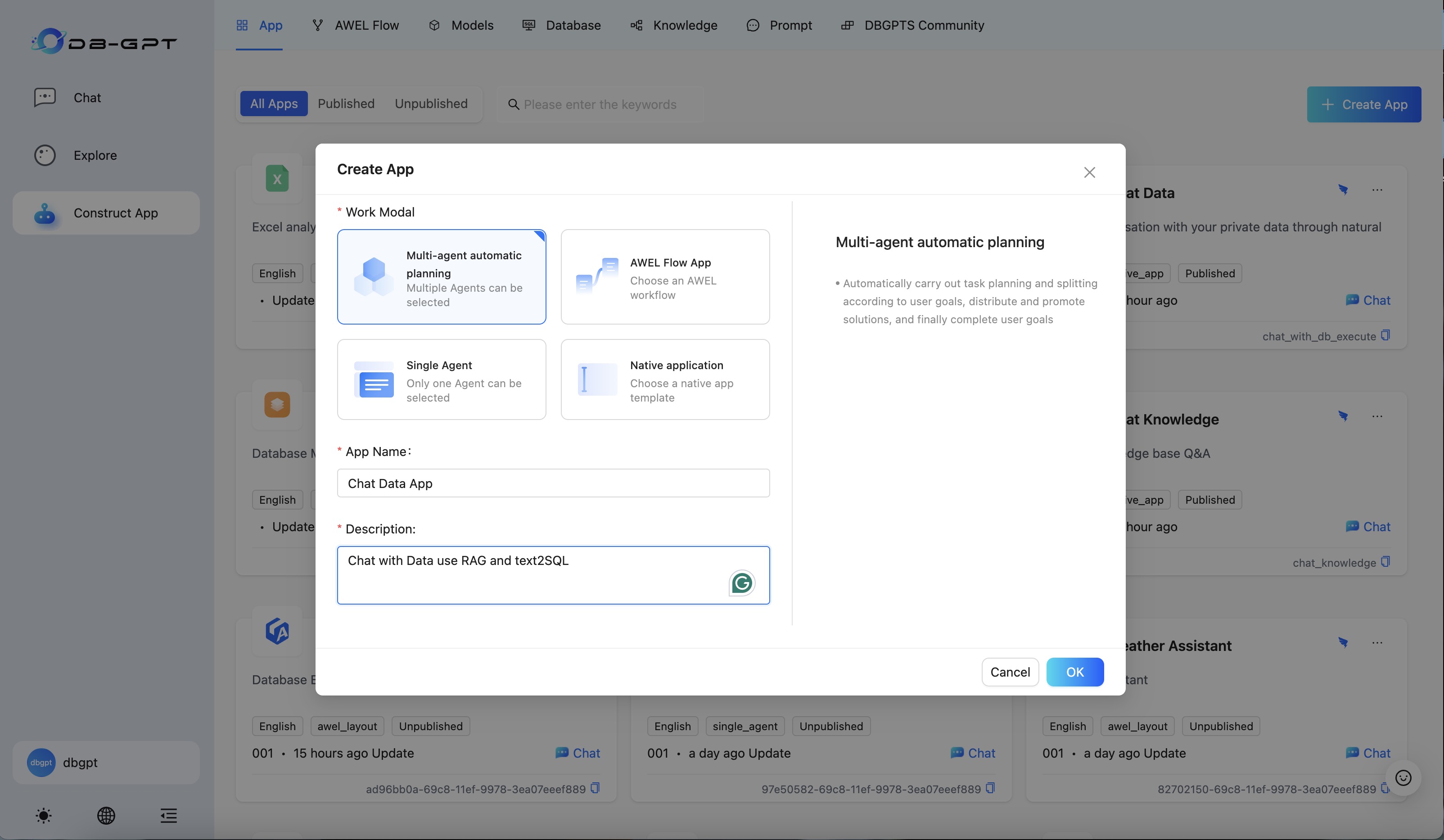
b. Create a Multi-agent+ Auto-Planning+ MCP web page scraping and summarization APP.
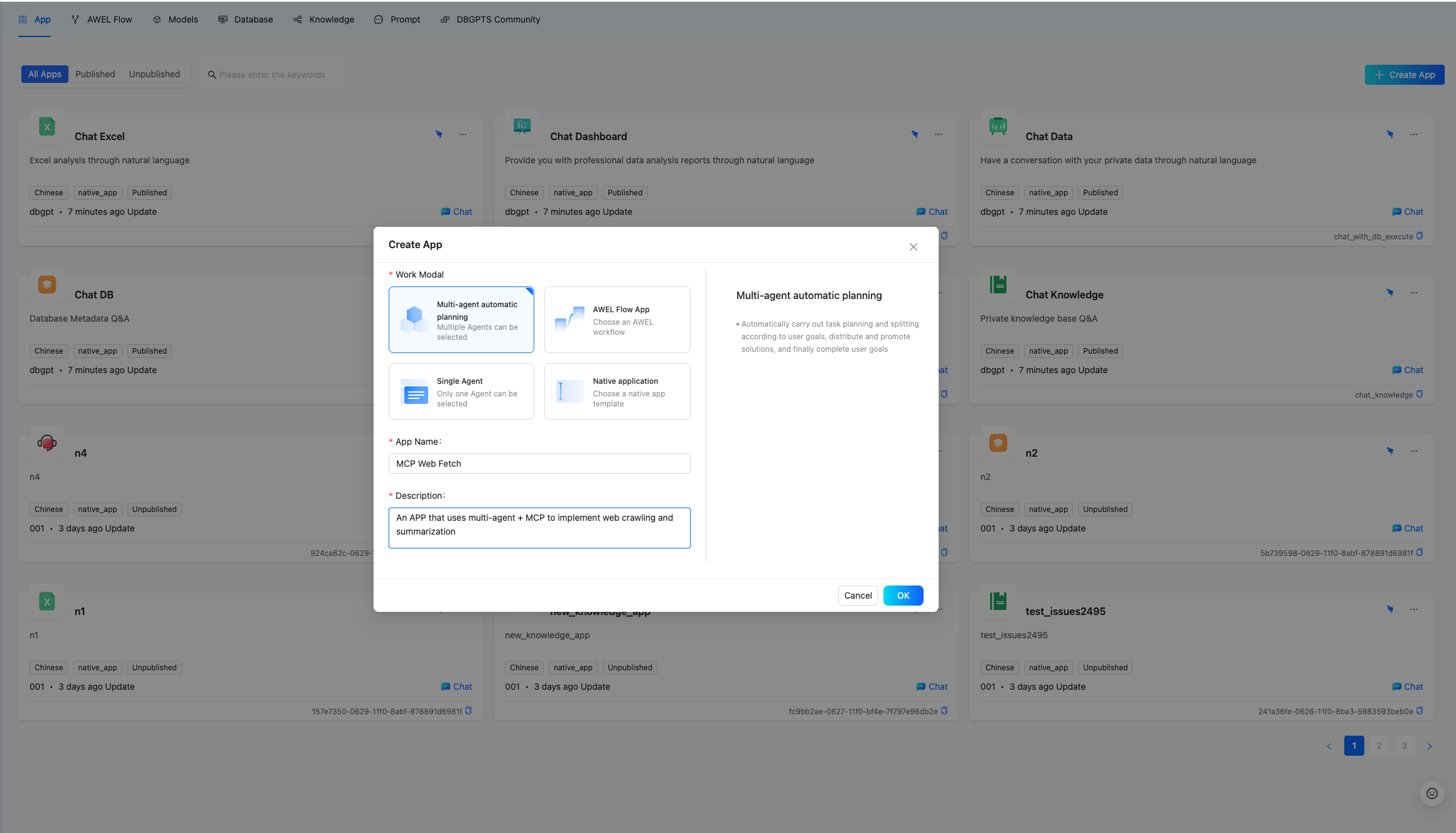
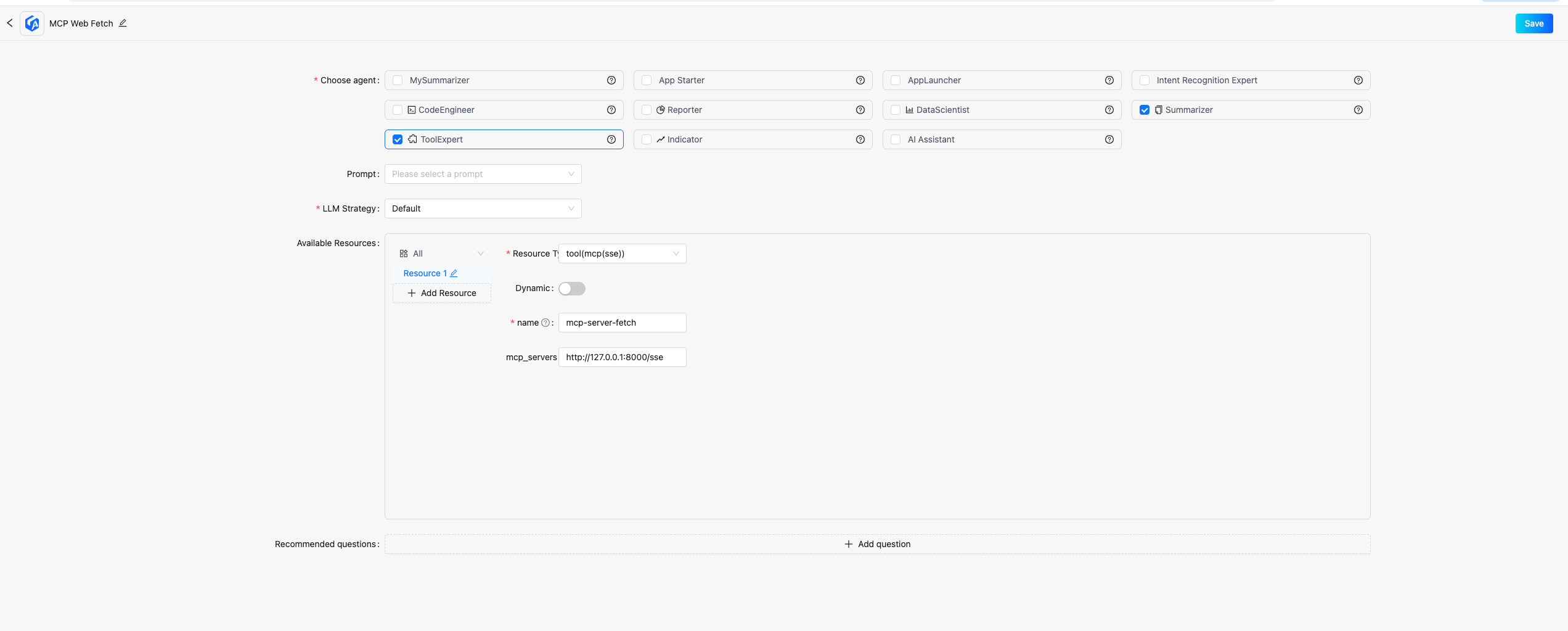
c. Configure the APP, select the ToolExpert and Summarizer agents, and add a resource of type tool(mcp(sse)) to ToolExpert, where mcp_servers should be filled with the service address started in step a (default is: http://127.0.0.1:8000/sse), then save the application.
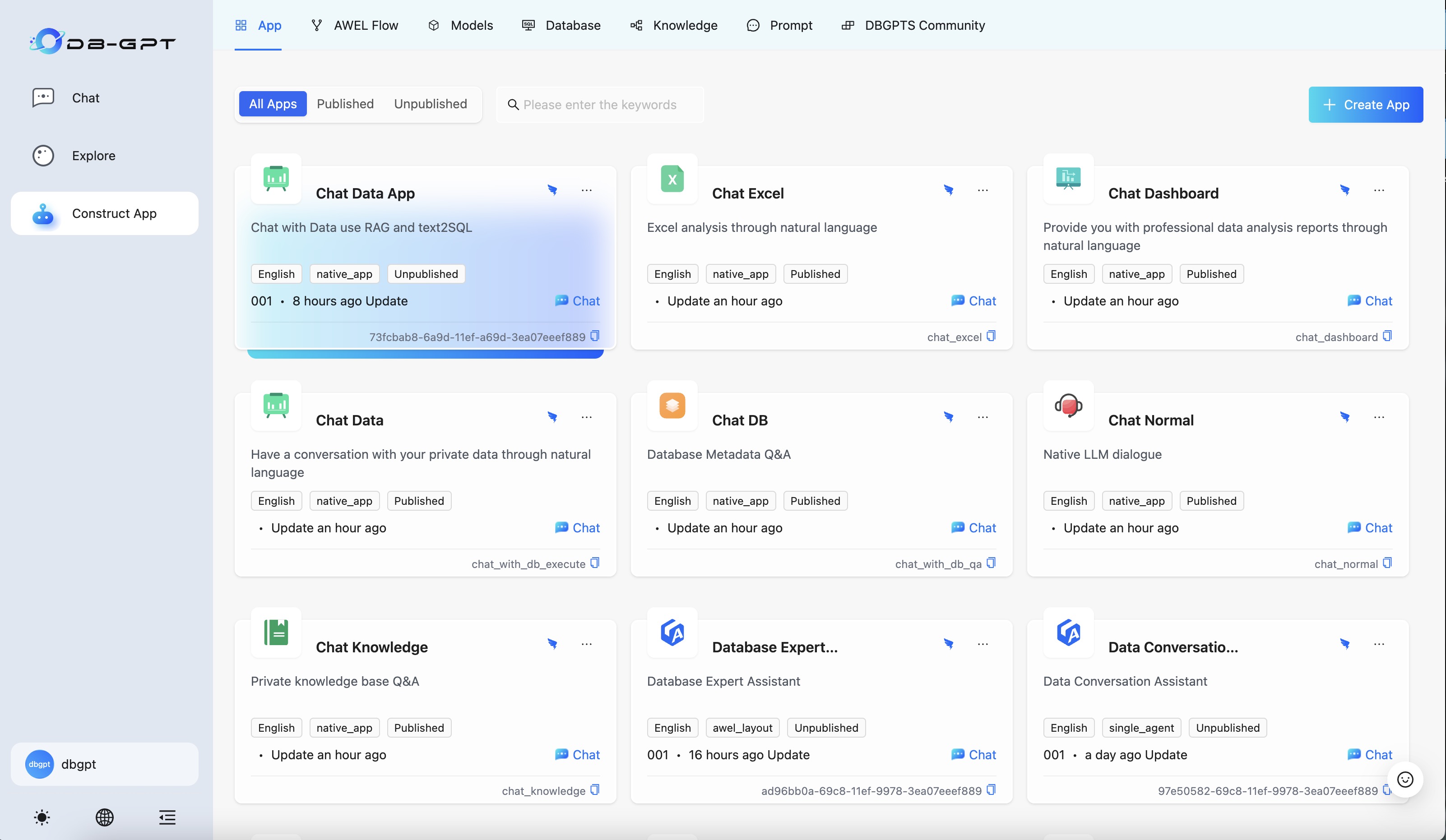
d. Select the newly created MCP Web Fetch APP to chat, provide a webpage for the APP to summarize:
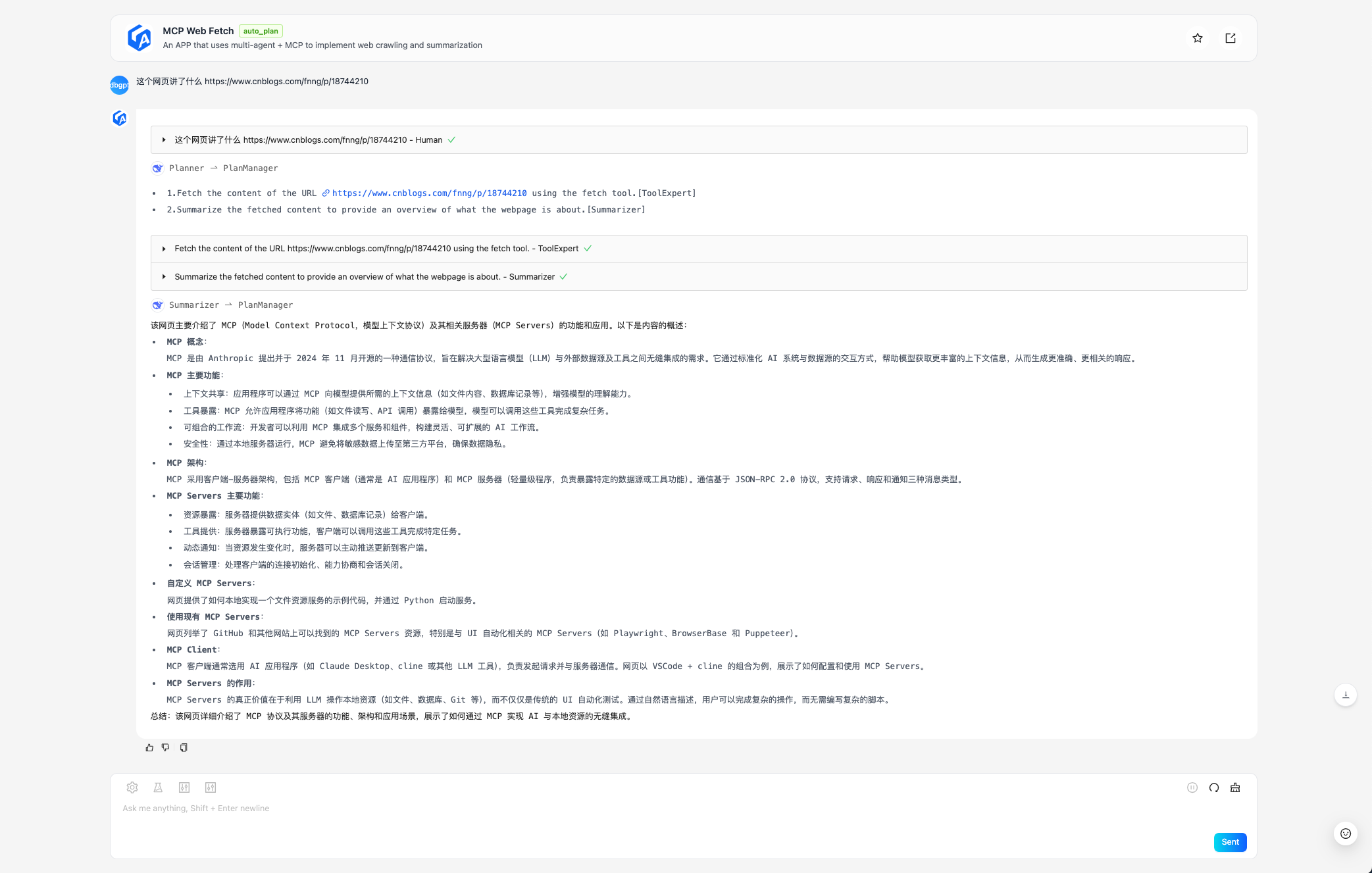
The example input question is: What does this webpage talk about https://www.cnblogs.com/fnng/p/18744210"
And all Chat scenarios in original DB-GPT now have deep thinking capabilities.
For quick usage reference: http://docs.dbgpt.cn/docs/next/quickstart
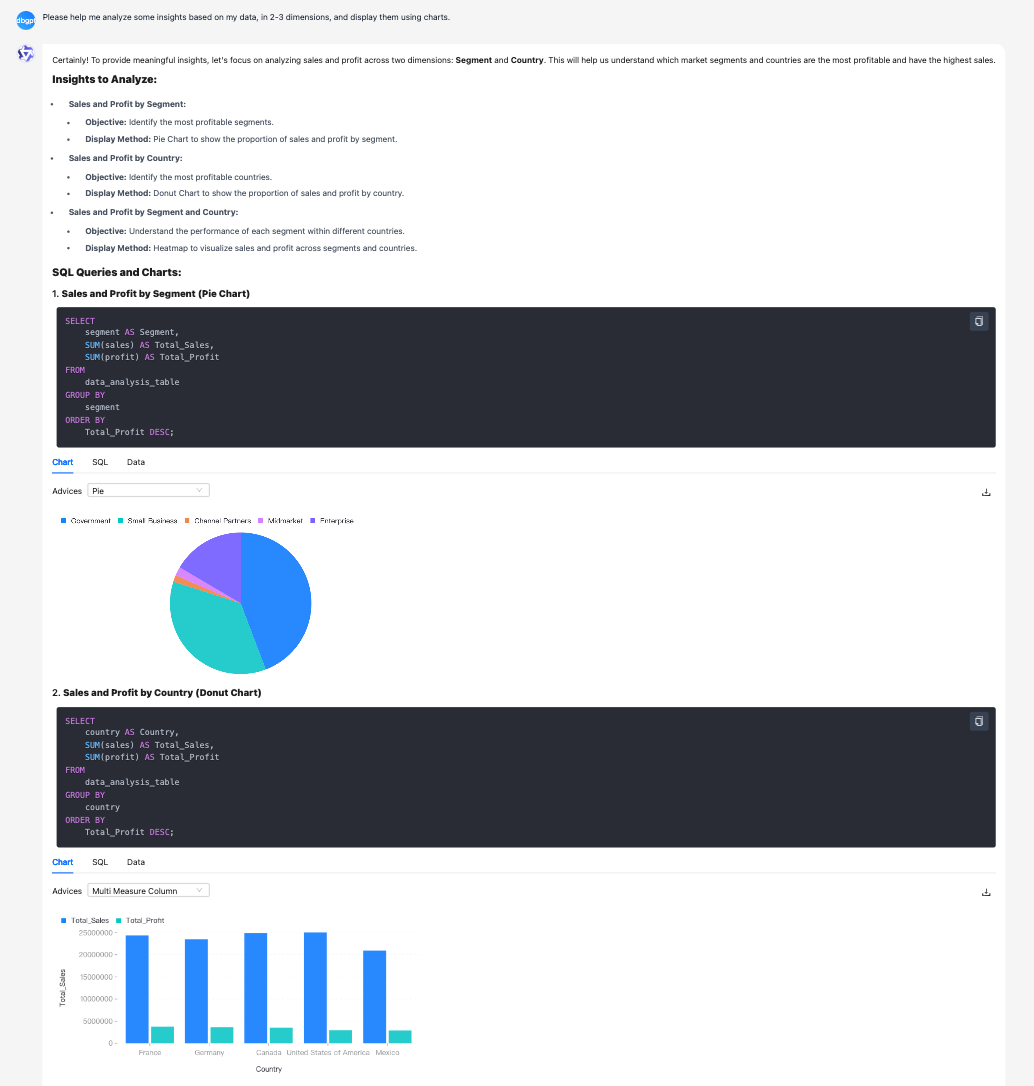
Data analysis scenario:
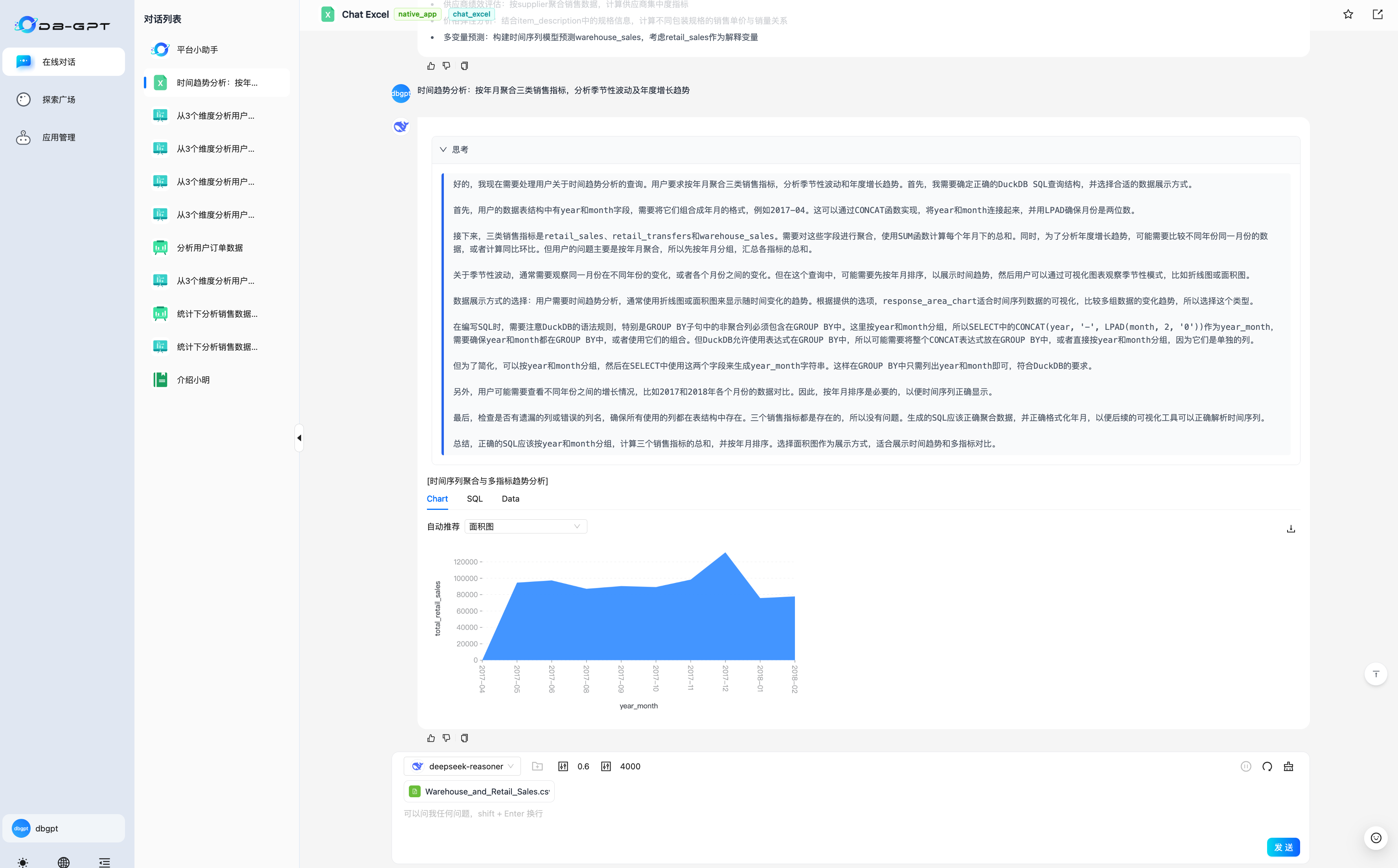
Knowledge base scenario:
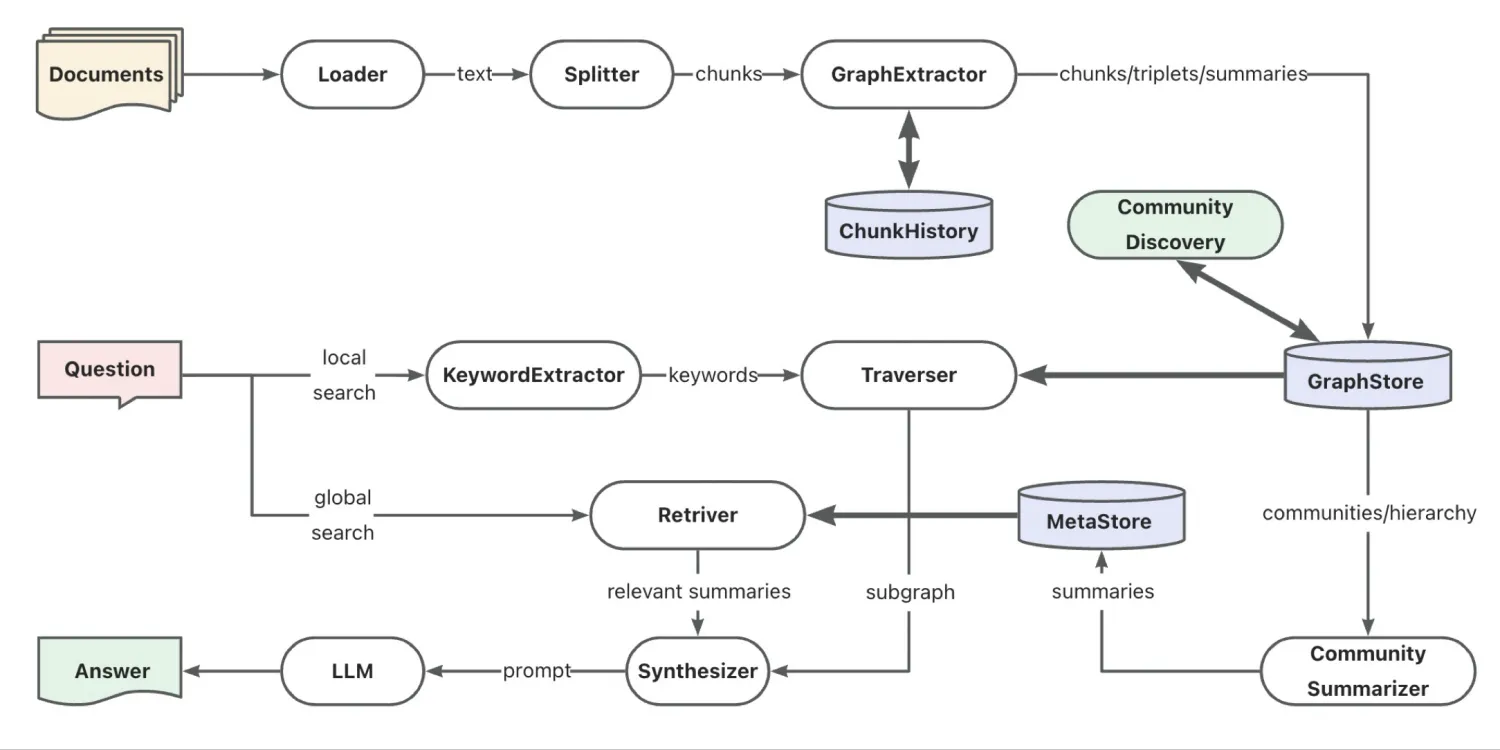
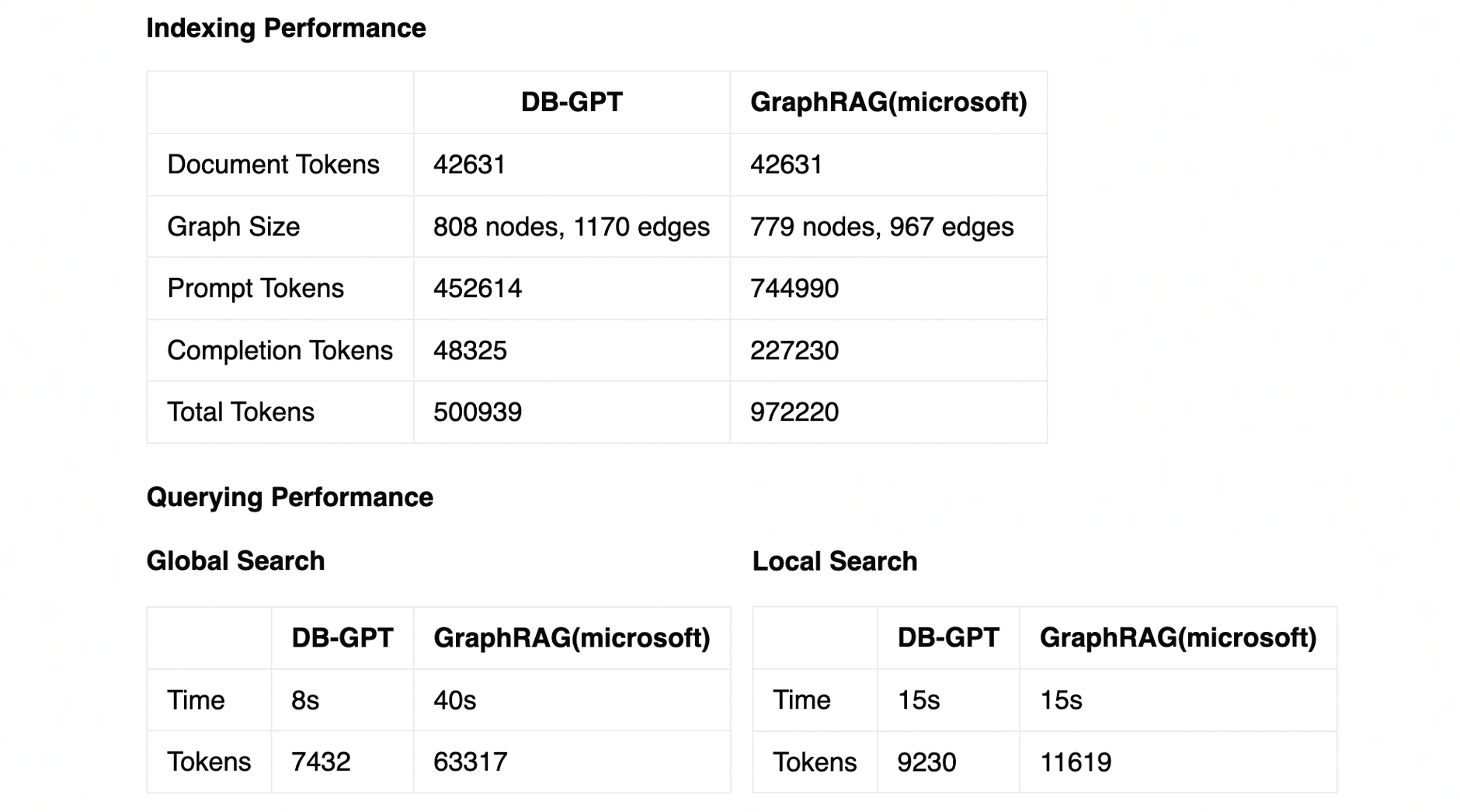
3. GraphRAG retrieval chain enhancement: support for "Vector" and "Intent Recognition+Text2GQL" graph retrievers.
During the knowledge graph construction process, vectors are added to all nodes and edges and indexes are established. When querying, the question is vectorized and through TuGraph-DB's built-in vector indexing capability, based on the HNSW algorithm, topk related nodes and edges are queried. Compared to keyword graph retrieval, it can identify more ambiguous questions.
Configuration example:
[rag.storage.graph]
type = "TuGraph"
host="127.0.0.1"
port=7687
username="admin"
password="73@TuGraph"
enable_summary="True"
triplet_graph_enabled="True"
document_graph_enabled="True"
# Vector graph retrieval configuration items
enable_similarity_search="True"
knowledge_graph_embedding_batch_size=20
similarity_search_topk=5
extract_score_threshold=0.7
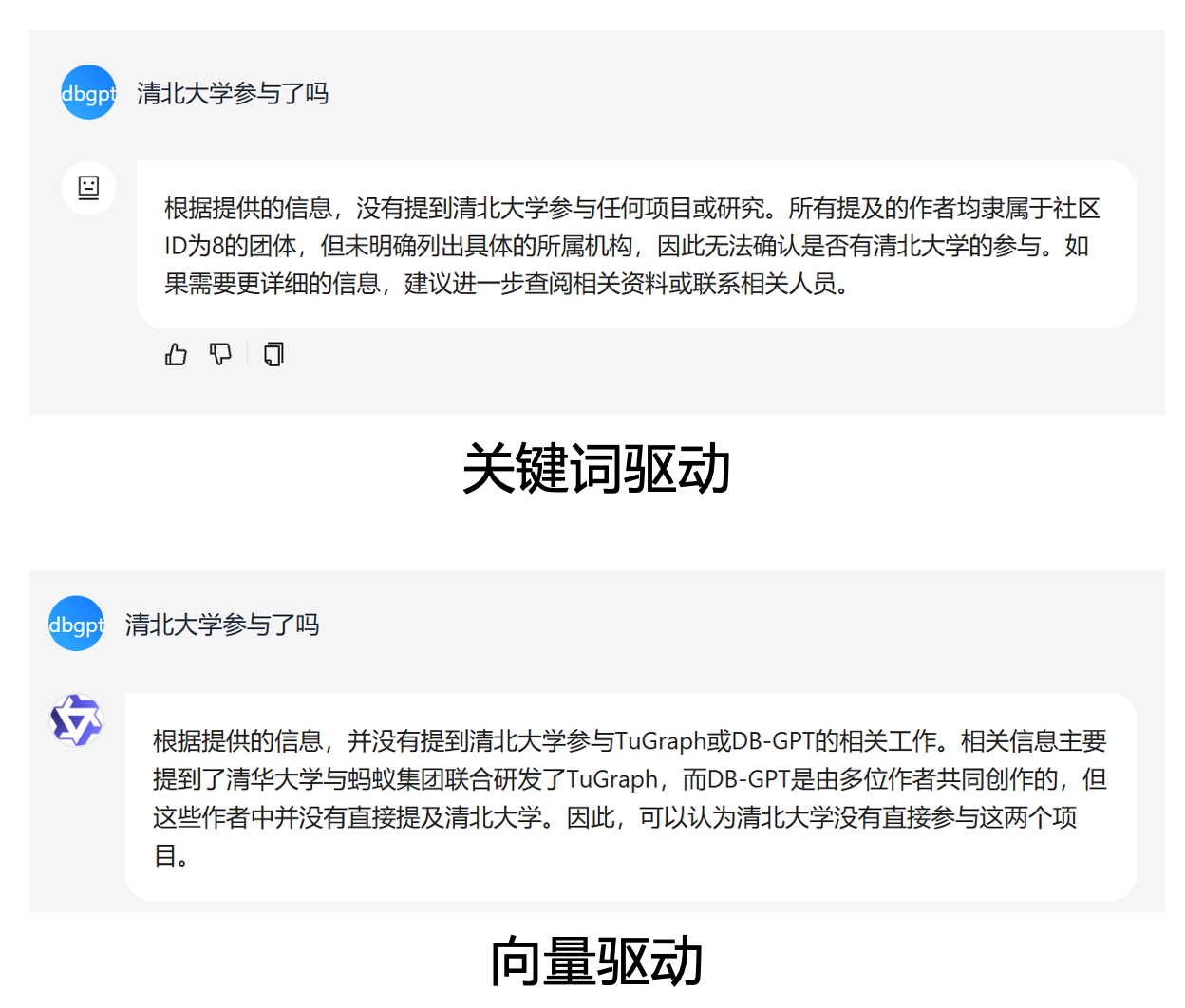
- "Intent Recognition+Text2GQL" graph retriever
The question is rewritten through the intent recognition module, extracting true intent and involved entities and relationships, and then translated using the Text2GQL model into GQL statements for direct querying. It can perform more precise graph queries and display corresponding query statements. In addition to calling large model API services, you can also use ollama to call local Text2GQL models.
Configuration example:
[rag.storage.graph]
type = "TuGraph"
host="127.0.0.1"
port=7687
username="admin"
password="73@TuGraph"
enable_summary="True"
triplet_graph_enabled="True"
document_graph_enabled="True"
# Intent Recognition+Text2GQL graph retrieval configuration items
enable_text_search="True"
# Use Ollama to deploy independent text2gql model, enable the following configuration items
# text2gql_model_enabled="True"
# text2gql_model_name="tugraph/CodeLlama-7b-Cypher-hf:latest"
Original dbgpt package split into dbgpt-core, dbgpt-ext, dbgpt-serve, dbgpt-client, dbgpt-acclerator, dbgpt-app
As dbgpt has gradually developed, the service modules have increased, making functional regression testing difficult and compatibility issues more frequent. Therefore, the original dbgpt content has been modularized:
- dbgpt-core: Mainly responsible for core module interface definitions of dbgpt's awel, model, agent, rag, storage, datasource, etc., releasing Python SDK.
- dbgpt-ext: Mainly responsible for implementing dbgpt extension content, including datasource extensions, vector-storage, graph-storage extensions, and model access extensions, making it easier for community developers to quickly use and extend new module content, releasing Python SDK.
- dbgpt-serve: Mainly provides Restful interfaces for dbgpt's atomized services of each module, making it easy for community users to quickly integrate. No Python SDK is released at this time.
- dbgpt-app: Mainly responsible for business scenario implementations such as
App, ChatData, ChatKnowledge, ChatExcel, Dashboard, etc., with no Python SDK.
- dbgpt-client: Provides a unified Python SDK client for integration.
- dbgpt-accelerator: Model inference acceleration module, including compatibility and adaptation for different versions (different torch versions, etc.), platforms (Windows, MacOS, and Linux), hardware environments (CPU, CUDA, and ROCM), inference frameworks (vLLM, llama.cpp), quantization methods (AWQ, bitsandbytes, GPTQ), and other acceleration modules (accelerate, flash-attn), providing cross-platform, installable underlying environments on-demand for other DB-GPT modules.
The new configuration files using ".toml" format, abolishing the original .env configuration logic, each module can have its own configuration class, and automatically generate front-end configuration pages.
For quick usage reference: http://docs.dbgpt.cn/docs/next/quickstart
For all configurations reference: http://docs.dbgpt.cn/docs/next/config-reference/app/config_chatdashboardconfig_2480d0
[system]
# Load language from environment variable(It is set by the hook)
language = "${env:DBGPT_LANG:-zh}"
api_keys = []
encrypt_key = "your_secret_key"
# Server Configurations
[service.web]
host = "0.0.0.0"
port = 5670
[service.web.database]
type = "sqlite"
path = "pilot/meta_data/dbgpt.db"
[service.model.worker]
host = "127.0.0.1"
[rag.storage]
[rag.storage.vector]
type = "chroma"
persist_path = "pilot/data"
# Model Configurations
[models]
[[models.llms]]
name = "deepseek-reasoner"
# name = "deepseek-chat"
provider = "proxy/deepseek"
api_key = "your_deepseek_api_key"
DB-GPT unified storage extension OSS and S3 implementation, where the S3 implementation supports most cloud storage compatible with the S3 protocol. DB-GPT knowledge base original files, Chat Excel related intermediate files, AWEL Flow node parameter files, etc. all support cloud storage.
Configuration example:
[[serves]]
type = "file"
# Default backend for file server
default_backend = "s3"
[[serves.backends]]
type = "oss"
endpoint = "https://oss-cn-beijing.aliyuncs.com"
region = "oss-cn-beijing"
access_key_id = "${env:OSS_ACCESS_KEY_ID}"
access_key_secret = "${env:OSS_ACCESS_KEY_SECRET}"
fixed_bucket = "{your_bucket_name}"
[[serves.backends]]
# Use Tencent COS s3 compatible API as the file server
type = "s3"
endpoint = "https://cos.ap-beijing.myqcloud.com"
region = "ap-beijing"
access_key_id = "${env:COS_SECRETID}"
access_key_secret = "${env:COS_SECRETKEY}"
fixed_bucket = "{your_bucket_name}
For detailed configuration instructions, please refer to: http://docs.dbgpt.cn/docs/next/config-reference/utils/config_s3storageconfig_f0cdc9
Based on llama.cpp HTTP Server, supporting continuous batching, multi-user parallel inference, etc., llama.cpp inference moves towards production systems.
Configuration example:
# Model Configurations
[models]
[[models.llms]]
name = "DeepSeek-R1-Distill-Qwen-1.5B"
provider = "llama.cpp.server"
# If not provided, the model will be downloaded from the Hugging Face model hub
# uncomment the following line to specify the model path in the local file system
# https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-1.5B-GGUF
# path = "the-model-path-in-the-local-file-system"
path = "models/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf
Currently, most models can be integrated on the DB-GPT page, with configuration information persistently saved and models automatically loaded when the service starts.
Optimized the model extension approach, requiring only a few lines of code to integrate new models.
Configuration example:
[app]
# Unified temperature configuration for all scenarios
temperature = 0.6
[[app.configs]]
name = "chat_excel"
# Use custom temperature configuration
temperature = 0.1
duckdb_extensions_dir = []
force_install = true
[[app.configs]]
name = "chat_normal"
memory = {type="token", max_token_limit=20000}
[[app.configs]]
name = "chat_with_db_qa"
schema_retrieve_top_k = 50
memory = {type="window", keep_start_rounds=0, keep_end_rounds=10}
- Chat Data, Chat Dashboard support for streaming output.
- Optimization of library table field knowledge processing and recall
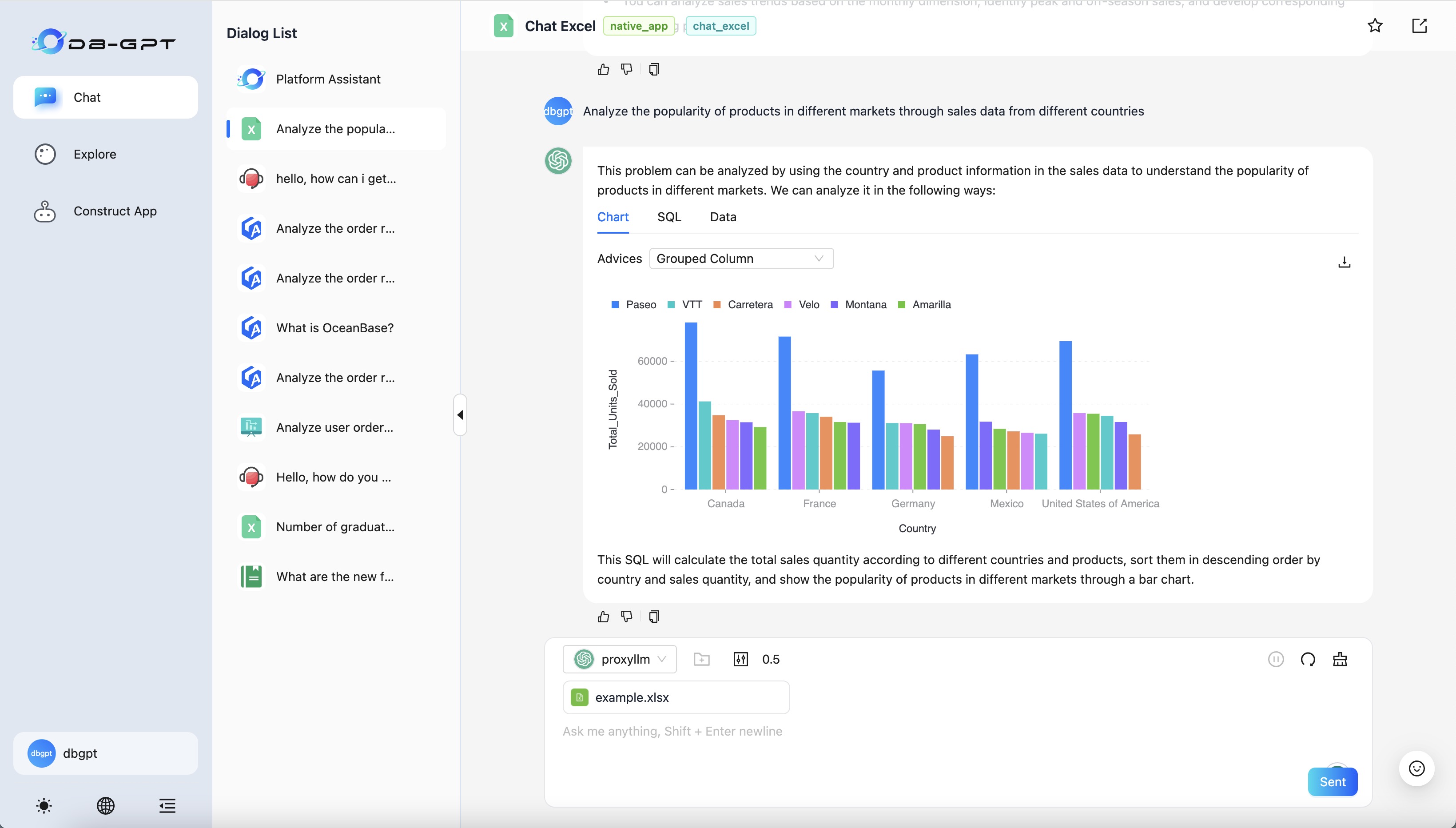
- Chat Excel optimization, supporting more complex table understanding and chart conversations, even small parameter-scale open-source LLMs can handle it well.
One-click deployment command for DB-GPT:
docker run -it --rm -e SILICONFLOW_API_KEY=${SILICONFLOW_API_KEY} \
-p 5670:5670 --name dbgpt eosphorosai/dbgpt-openai
You can also use the build script to build your own image:
bash docker/base/build_image.sh --install-mode openai
For details, see the documentation: http://docs.dbgpt.cn/docs/next/installation/docker-build-guide
from openai import OpenAI
DBGPT_API_KEY = "dbgpt"
client = OpenAI(
api_key=DBGPT_API_KEY,
base_url="http://localhost:5670/api/v2",
)
messages = [
{
"role": "user",
"content": "Hello, how are you?",
},
]
has_thinking = False
reasoning_content = ""
for chunk in client.chat.completions.create(
model="deepseek-chat",
messages=messages,
extra_body={
"chat_mode": "chat_normal",
},
stream=True,
max_tokens=4096,
):
delta_content = chunk.choices[0].delta.content
if hasattr(chunk.choices[0].delta, "reasoning_content"):
reasoning_content = chunk.choices[0].delta.reasoning_content
if reasoning_content:
if not has_thinking:
print("<thinking>", flush=True)
print(reasoning_content, end="", flush=True)
has_thinking = True
if delta_content:
if has_thinking:
print("</thinking>", flush=True)
print(delta_content, end="", flush=True)
has_thinking = False
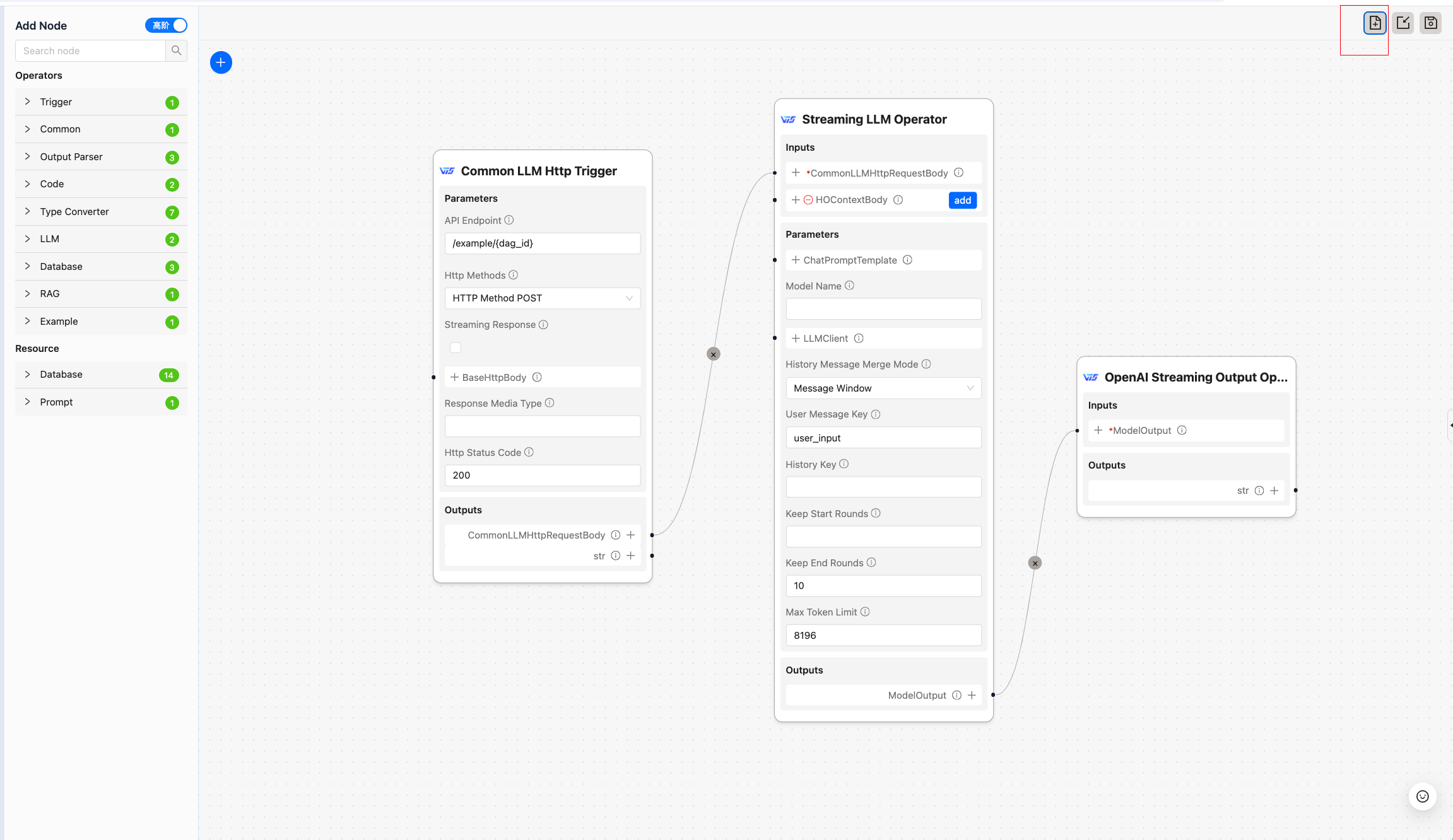
After the backend supports new data sources, the frontend can automatically identify and dynamically configure them.
Frontend automatically identifies resource configuration parameters while remaining compatible with old configurations.
IndexStore configuration restructuring, new storage implementations automatically scanned and discovered
Cross-version compatibility for AWEL flow based on multi-version metadata.
Chroma support for Chinese knowledge base spaces, AWEL Flow issue fixes, fixed multi-platform Lyric installation error issues and local embedding model error issues, along with 40+ other bugs.
Support for Ruff code formatting, multi-version documentation building, unit test fixes, and 20+ other issue fixes or feature enhancements.
Upgrade Guide:
For SQLite upgrades, table structures will be automatically upgraded by default. For MySQL upgrades, DDL needs to be executed manually. The assets/schema/dbgpt.sql file contains the complete DDL for the current version. Specific version change DDLs can be found in the assets/schema/upgrade directory. For example, if you are upgrading from v0.6.3 to v0.7.0, you can execute the following DDL:
mysql -h127.0.0.1 -uroot -p{your_password} < ./assets/schema/upgrade/v0_7_0/upgrade_to_v0.7.0.sql
Due to underlying changes in Chroma storage in v0.7.0, version 0.7.0 does not support reading content from older versions. Please re-import knowledge bases and refresh data sources. Other vector storage solutions are not affected.
English
Overview | DB-GPT
Chinese
概览
Thanks to all contributors for making this release possible!
283569391@qq.com, @15089677014, @Aries-ckt, @FOkvj, @Jant1L, @SonglinLyu, @TenYearOldJAVA, @Weaxs, @cinjoseph, @csunny, @damonqin, @dusx1981, @fangyinc, @geebytes, @haawha, @utopia2077, @vnicers, @xuxl2024, @yhjun1026, @yunfeng1993, @yyhhyyyyyy and tam

This version took nearly three months to develop and has been merged to the main branch for over a month. Hundreds of users participated in testing version 0.7.0, with GitHub receiving hundreds of issues feedback. Some users directly submitted PR fixes. The DB-GPT community sincerely thanks every user and contributor who participated in version 0.7.0!