DB-GPT V0.6.0, Defining new standards for AI-native data applications.
Introduction
DB-GPT is an open source AI native data application development framework with AWEL and agents. In the V0.6.0 version, we further provide flexible and scalable AI native data application management and development capabilities around large models, which can help enterprises quickly build and deploy intelligent AI data applications, and achieve enterprise digital transformation and business growth through intelligent data analysis, insights and decisions
The V0.6.0 version mainly adds and enhances the following core features
-
AWEL protocol upgrade 2.0, supporting more complex orchestration
-
Supports the creation and lifecycle management of data applications, and supports multiple application construction modes, such as: multi-agent automatic planning mode, task flow orchestration mode, single agent mode, and native application mode
-
GraphRAG supports graph community summary and hybrid retrieval, and the graph index cost is reduced by 50% compared to Microsoft GraphRAG.
-
Supports multiple Agent Memories, such as perceptual memory, short-term memory, long-term memory, hybrid memory, etc.
-
Supports intent recognition and prompt management, and newly added support for Text2NLU and Text2GQL fine-tuning
-
GPT-Vis front-end visualization upgrade to support richer visualization charts
Features
AWEL protocol upgrade 2.0 supports more complex orchestration and optimizes front-end visualization and interaction capabilities.
AWEL (Agentic Workflow Expression Language) is an agent-based workflow expression language designed specifically for large model application development, providing powerful functions and flexibility. Through the AWEL API, developers can focus on large model application logic development without having to pay attention to cumbersome model, environment and other details. In AWEL2.0, we support more complex orchestration and visualization
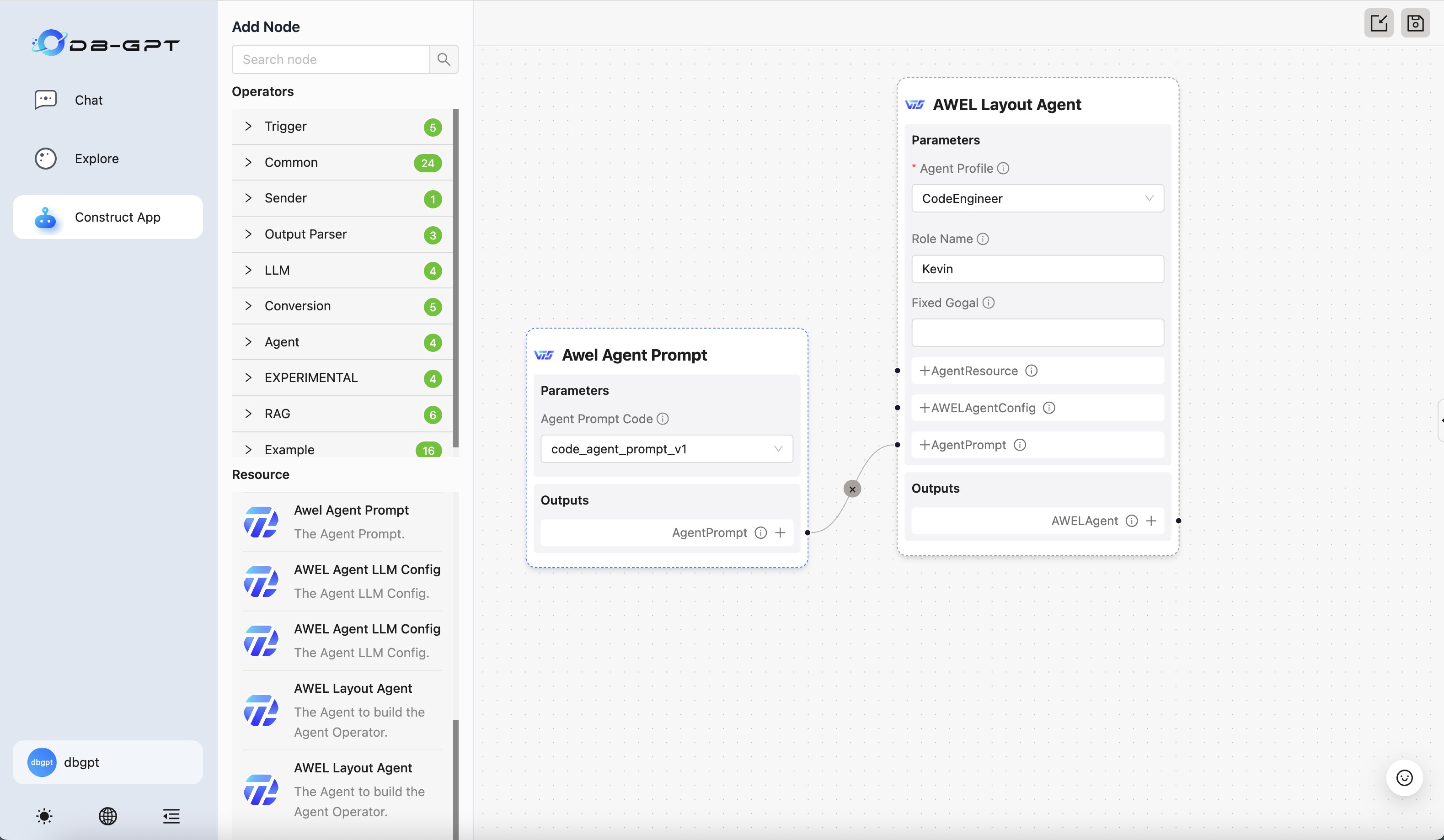
Supports the creation and life cycle management of data applications, and supports multiple modes to build applications, such as: multi-agent automatic planning mode, task flow orchestration mode, single agent mode, and native application mode
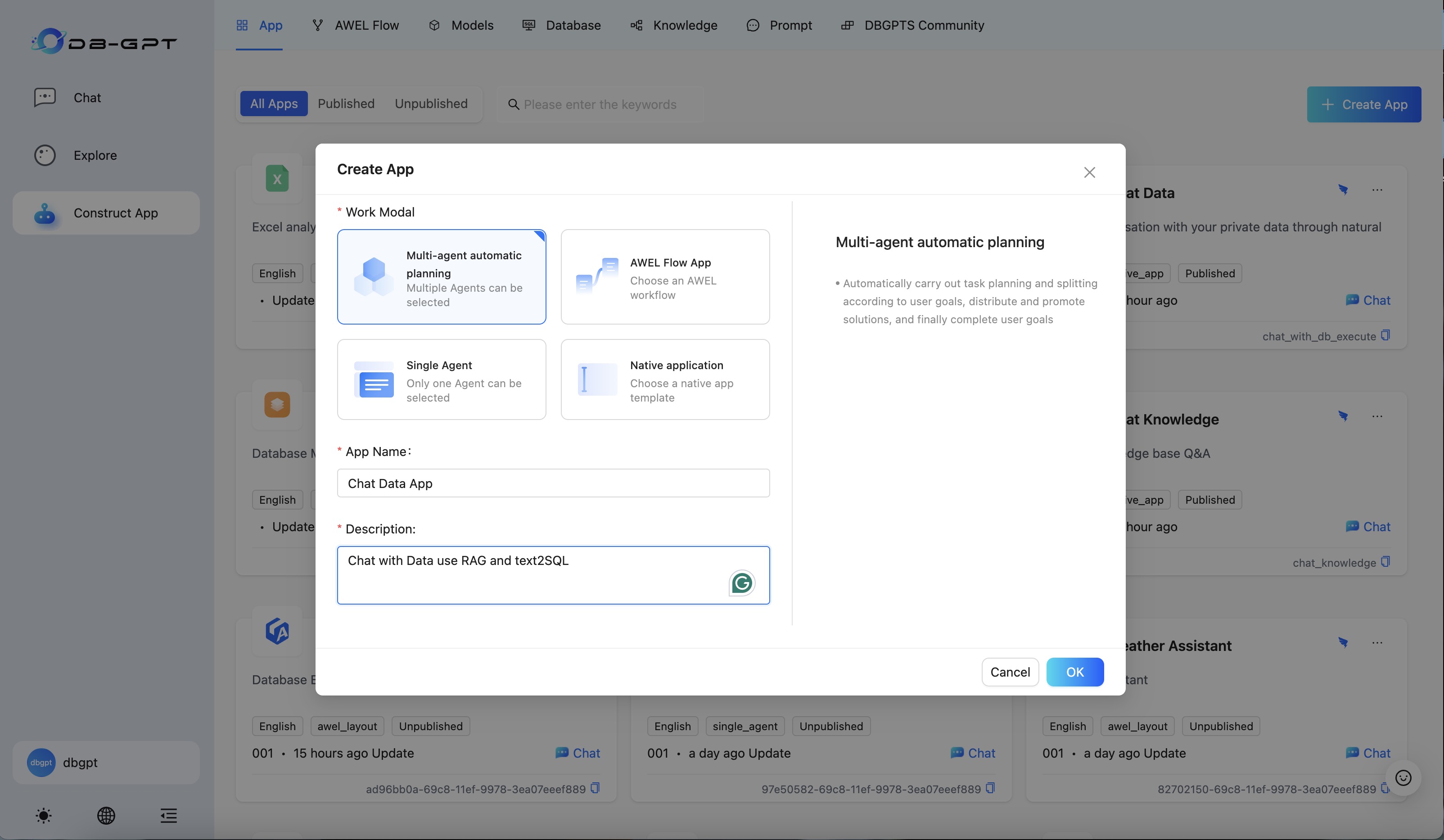
GraphRAG supports graph community summarization and hybrid retrieval.
The graph construction and retrieval performance have obvious advantages compared to community solutions, and it supports cool visualization. GraphRAG is an enhanced retrieval generation system based on knowledge graphs. Through the construction and retrieval of knowledge graphs, it further enhances the accuracy of retrieval and the stability of recall, while reducing the illusion of large models and enhancing the effects of domain applications. DB-GPT combines with TuGraph to build efficient retrieval enhancement generation capabilities
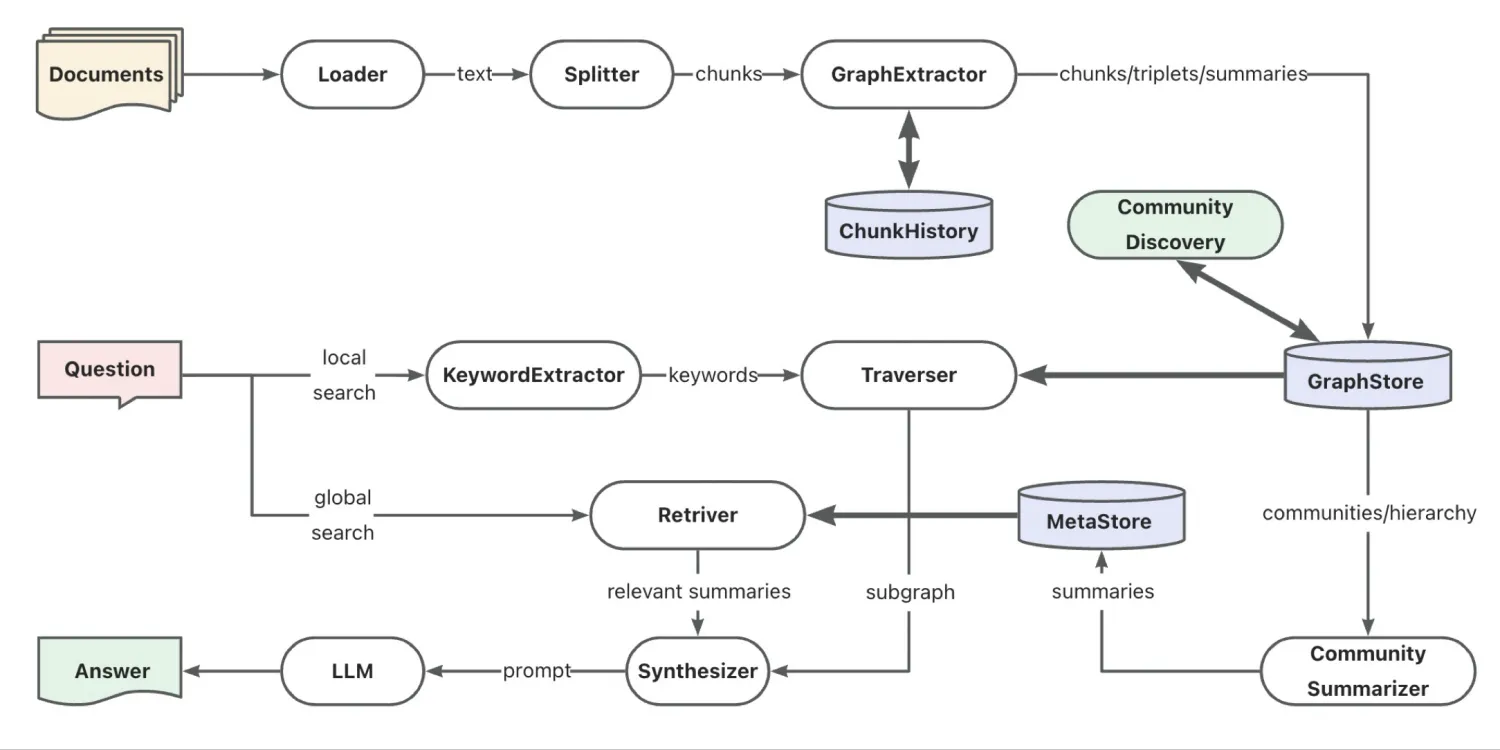
Based on the universal RAG framework launched in DB-GPT version 0.5.6 that integrates vector index, graph index, and full-text index, DB-GPT version 0.6.0 has enhanced the capabilities of graph index (GraphRAG) to support graph community summary and hybrid retrieval. ability. In the new version, we introduced TuGraph’s built-in Leiden community discovery algorithm, combined with large models to extract community subgraph summaries, and finally used similarity recall of community summaries to cope with generalized questioning scenarios, namely QFS (Query Focused Summarization). question. In addition, in the knowledge extraction stage, we upgraded the original triple extraction to graph extraction with point edge information summary, and optimized cross-text block associated information extraction through text block history to further enhance the information density of the knowledge graph.
Based on the above design, we used the open source knowledge graph corpus (OSGraph) provided by the TuGraph community and the product introduction materials of DB-GPT and TuGraph (about 43k tokens in total), and conducted comparative tests with Microsoft's GraphRAG system. Finally, DB-GPT It only consumes 50% of the token overhead and generates a knowledge graph of the same scale. And on the premise that the quality of the question and answer test is equivalent, the global search performance has been significantly improved.
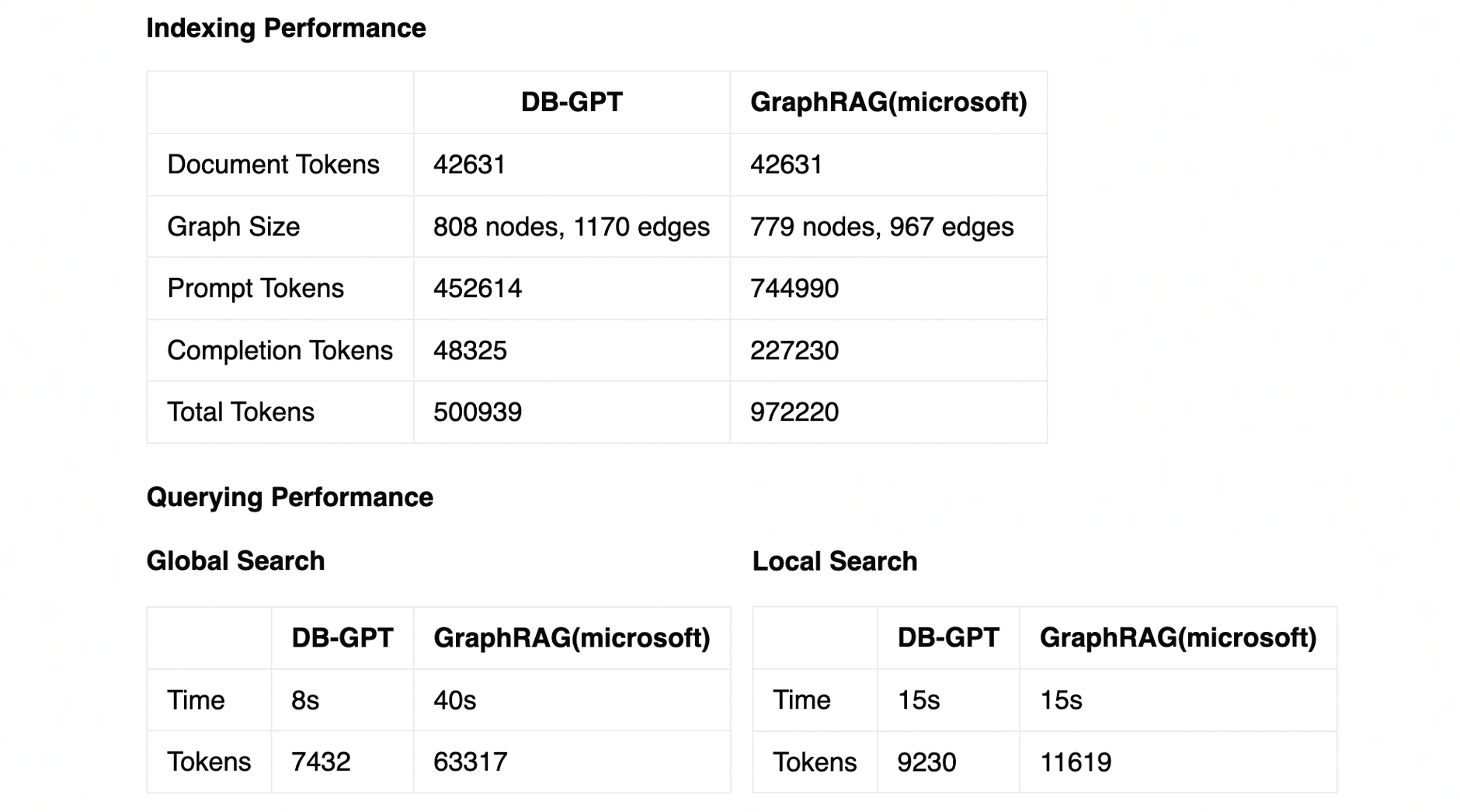
For the final generated knowledge graph, we used AntV's G6 engine to upgrade the front-end rendering logic, which can intuitively preview the knowledge graph data and community segmentation results.
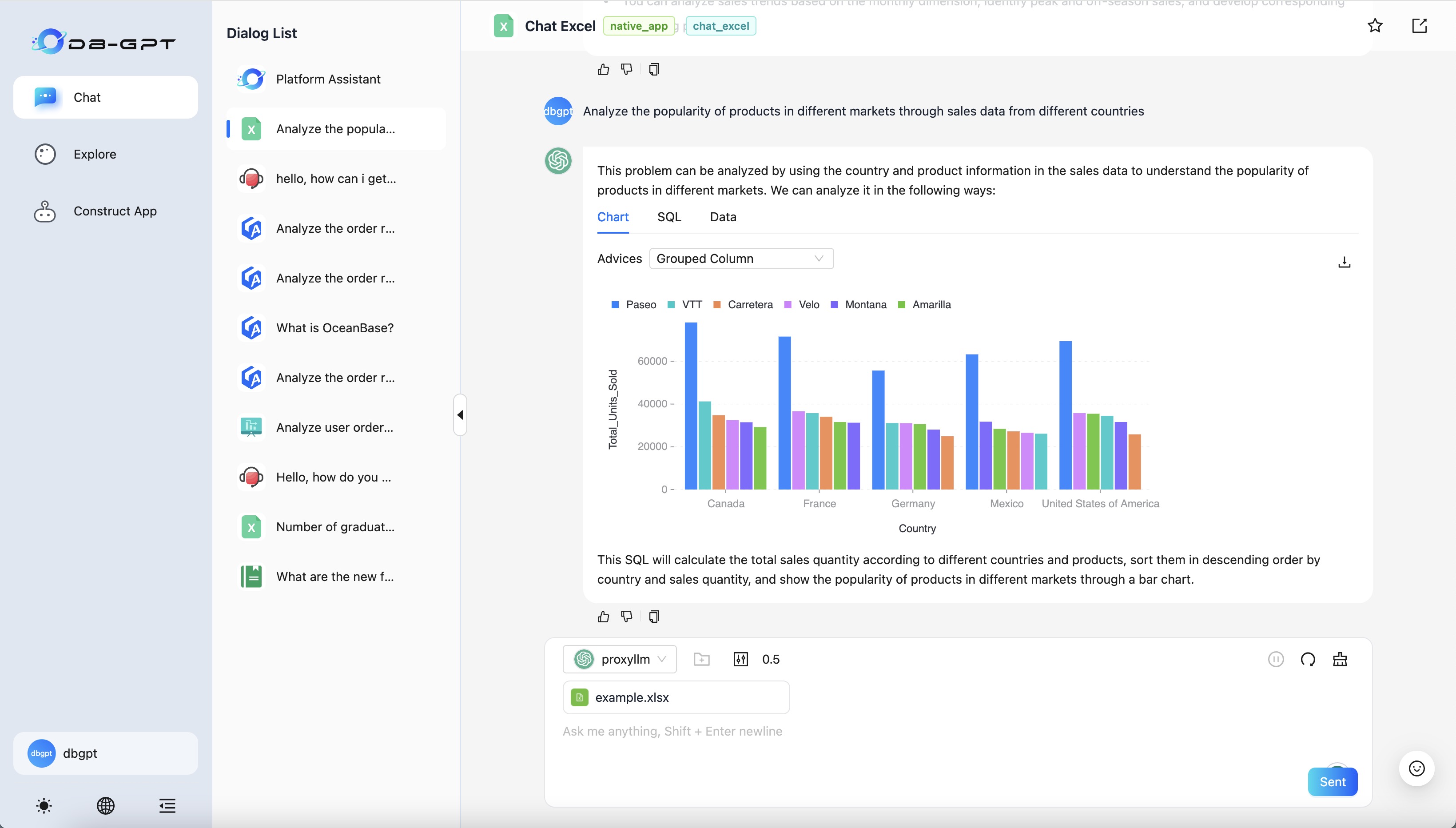
GPT-Vis: GPT-Vis is an interactive visualization solution for LLM and data, supporting rich visual chart display and intelligent recommendations
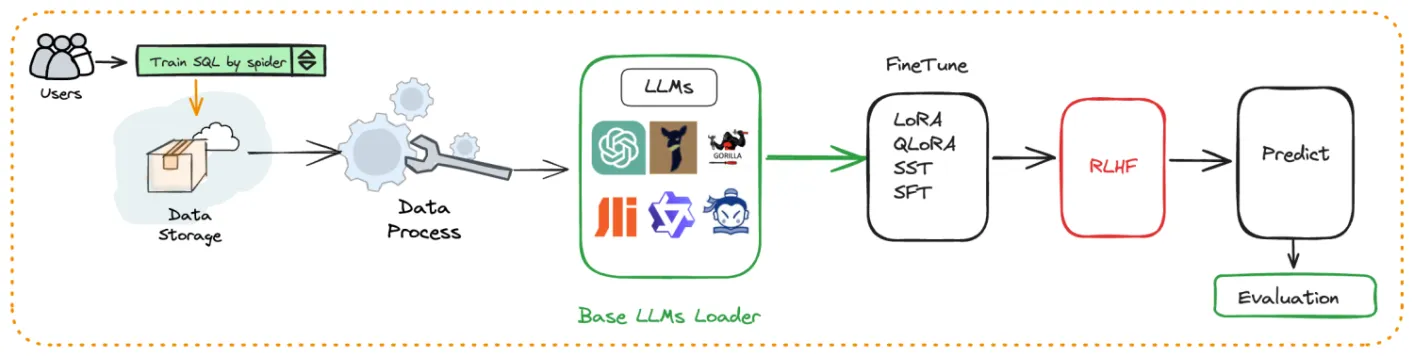
Text2GQL and Text2NLU fine-tuning: Newly supports fine-tuning from natural language to graph language, as well as fine-tuning for semantic classification.
Acknowledgements
This iteration is inseparable from the participation of developers and users in the community, and it also further cooperates with the TuGraph and AntV communities. Thanks to all the contributors who made this release possible!
@Aries-ckt, @Dreammy23, @Hec-gitHub, @JxQg, @KingSkyLi, @M1n9X, @bigcash, @chaplinthink, @csunny, @dusens, @fangyinc, @huangjh131, @hustcc, @lhwan, @whyuds and @yhjun1026