Data Driven Multi-Agents
Introduction
DB-GPT agent is a data-driven multi-agent system that aims to provide a production-level agent development framework. We believe that production-level agent applications need to be based on data-driven decisions and can be orchestrated in a controllable agentic workflow.
Multi-Level API Design
- Python agent API: Build an agents application with Python code, you just need install
dbgptpackage withpip install "dbgpt[agent]" - Application API: Build an agents application in DB-GPT project, you can use all the capabilities of other modules in DB-GPT project.
Most of the time, you can use the Python agent API to build your agents application in a simple way, only a little change to the code when you need to deploy your agents to production.
Quick Start
Installation
Firstly, you need to install the dbgpt package with the following command:
pip install "dbgpt[agent,simple_framework]>=0.7.0" "dbgpt_ext>=0.7.0"
Then, you can install the openai package with the following command:
pip install openai
Write Your First Calculator With Agent
The LLM is the "brain" of the agent, now we use the OpenAI LLM. In DB-GPT agents, you can use all models then supported by DB-GPT, whether they are locally deployed LLMs or proxy models, whether they are deployed on a single machine or in a cluster.
import os
from dbgpt.model.proxy import OpenAILLMClient
llm_client = OpenAILLMClient(
model_alias="gpt-3.5-turbo", # or other models, eg. "gpt-4o"
api_base=os.getenv("OPENAI_API_BASE"),
api_key=os.getenv("OPENAI_API_KEY"),
)
Then, you should create an agent context and agent memory.
from dbgpt.agent import AgentContext, AgentMemory
# language="zh" for Chinese
context: AgentContext = AgentContext(
conv_id="test123", language="en", temperature=0.5, max_new_tokens=2048
)
# Create an agent memory, default memory is ShortTermMemory
agent_memory: AgentMemory = AgentMemory()
Memory stores information perceived from the environment and leverages the recorded
memories to facilitate future actions.
Default memory is ShortTermMemory, it just keeps the latest k turns of the conversation.
Your can use other memory, such as LongTermMemory, SensoryMemory and HybridMemory, we will introduce them later.
Then, you can create a code assistant agent and a user proxy agent.
import asyncio
from dbgpt.agent import LLMConfig, UserProxyAgent
from dbgpt.agent.expand.code_assistant_agent import CodeAssistantAgent
async def main():
# Create a code assistant agent
coder = (
await CodeAssistantAgent()
.bind(context)
.bind(LLMConfig(llm_client=llm_client))
.bind(agent_memory)
.build()
)
# Initialize GptsMemory
agent_memory.gpts_memory.init(conv_id="test123")
# Create a user proxy agent
user_proxy = await UserProxyAgent().bind(context).bind(agent_memory).build()
# Initiate a chat with the user proxy agent
await user_proxy.initiate_chat(
recipient=coder,
reviewer=user_proxy,
message="Calculate the result of 321 * 123",
)
# Obtain conversation history messages between agents
print(await agent_memory.gpts_memory.app_link_chat_message("test123"))
if __name__ == "__main__":
asyncio.run(main())
You will see the following output:
--------------------------------------------------------------------------------
User (to Turing)-[]:
"Calculate the result of 321 * 123"
--------------------------------------------------------------------------------
un_stream ai response: ```python
# filename: calculate_multiplication.py
result = 321 * 123
print(result)
```
>>>>>>>> EXECUTING CODE BLOCK 0 (inferred language is python)...
execute_code was called without specifying a value for use_docker. Since the python docker package is not available, code will be run natively. Note: this fallback behavior is subject to change
un_stream ai response: True
--------------------------------------------------------------------------------
Turing (to User)-[gpt-3.5-turbo]:
"```python\n# filename: calculate_multiplication.py\n\nresult = 321 * 123\nprint(result)\n```"
>>>>>>>>Turing Review info:
Pass(None)
>>>>>>>>Turing Action report:
execution succeeded,
39483
--------------------------------------------------------------------------------
```agent-plans
[{"name": "Calculate the result of 321 * 123", "num": 1, "status": "complete", "agent": "Human", "markdown": "```agent-messages\n[{\"sender\": \"CodeEngineer\", \"receiver\": \"Human\", \"model\": \"gpt-3.5-turbo\", \"markdown\": \"```vis-code\\n{\\\"exit_success\\\": true, \\\"language\\\": \\\"python\\\", \\\"code\\\": [[\\\"python\\\", \\\"# filename: calculate_multiplication.py\\\\n\\\\nresult = 321 * 123\\\\nprint(result)\\\"]], \\\"log\\\": \\\"\\\\n39483\\\\n\\\"}\\n```\"}]\n```"}]
```
In DB-GPT agents, most core interfaces are asynchronous for high performance.
So we will write all the code to build the agent in an asynchronous way. In development,
you can use the asyncio.run(main()) to run the agent.
Here is the graph of above code:
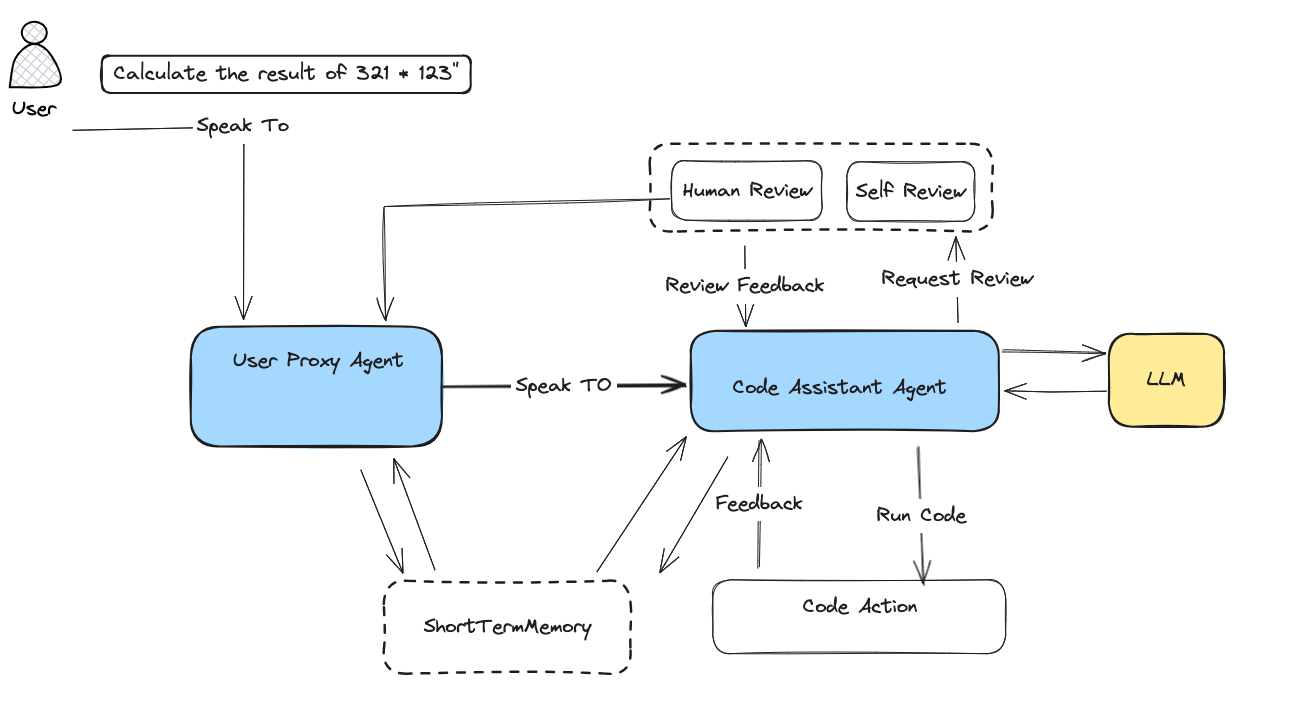
In the above code, we create a CodeAssistantAgent and a UserProxyAgent.
UserProxyAgent is a proxy of the user, it is an admin agent that can initiate a chat
with other agents, and it can review the feedback of the agents.
CodeAssistantAgent is a code assistant agent, it will generate some codes to solve
the question of the user, in this case, it will generate a Python code to calculate the
result of 321 * 123, then the code will be executed in its internal CodeAction, the
result will be returned to the user if it is reviewed passed.
In the end of the code, we print the conversation history messages between agents.
What's Next�
- How to use tools in DB-GPT agents
- How to connect to the database in DB-GPT agents
- How to use planning in DB-GPT agents
- How to use various memories in DB-GPT agents
- How to write a custom agent in DB-GPT agents
- How to integrate agents with AWEL(Agentic Workflow Expression Language)
- How to deploy agents in production