DB-GPT 数据分析应用实践案例
本实践案例旨在帮助入门者使用 DB-GPT 创建数据分析的多智能体应用对 Superstore 数据集进行分析。通过本案例,您将学会如何部署项目、配置环境、准备数据,并成功运行针对 Superstore 销售数据的分析应用。
1. 项目部署
1.1 克隆代码库
首先,从 GitHub 克隆 DB-GPT 项目代码:
git clone https://github.com/eosphoros-ai/DB-GPT.git
cd DB-GPT
1.2 环境准备
DB-GPT 支持多种部署方式,推荐使用 uv 工具进行依赖管理:
# 安装 uv 工具
curl -LsSf https://astral.sh/uv/install.sh | sh
# 验证安装
uv --version
1.3 安装依赖
根据您使用的模型类型,选择相应的依赖安装方式:
使用 OpenAI 代理模型
uv sync --all-packages \
--extra "base" \
--extra "proxy_openai" \
--extra "rag" \
--extra "storage_chromadb" \
--extra "dbgpts"
使用本地模型(如 GLM4)
uv sync --all-packages \
--extra "base" \
--extra "cuda121" \
--extra "hf" \
--extra "rag" \
--extra "storage_chromadb" \
--extra "quant_bnb" \
--extra "dbgpts"
1.4 配置大语言模型和嵌入模型
OpenAI 代理模型配置
创建或编辑配置文件 configs/dbgpt-proxy-openai.toml:
[system]
language = "zh"
encrypt_key = "your_secret_key"
[service.web]
host = "0.0.0.0"
port = 5670
[service.web.database]
type = "sqlite"
path = "pilot/meta_data/dbgpt.db"
[rag.storage]
[rag.storage.vector]
type = "chroma"
persist_path = "pilot/data"
# 模型配置
[models]
[[models.llms]]
name = "gpt-3.5-turbo"
provider = "proxy/openai"
api_key = "your-openai-api-key"
[[models.embeddings]]
name = "text-embedding-ada-002"
provider = "proxy/openai"
api_key = "your-openai-api-key"
本地模型配置示例
创建或编辑配置文件 configs/dbgpt-local-glm.toml:
[system]
language = "zh"
encrypt_key = "your_secret_key"
[service.web]
host = "0.0.0.0"
port = 5670
[service.web.database]
type = "sqlite"
path = "pilot/meta_data/dbgpt.db"
[rag.storage]
[rag.storage.vector]
type = "chroma"
persist_path = "pilot/data"
# 模型配置
[models]
[[models.llms]]
name = "THUDM/glm-4-9b-chat-hf"
provider = "hf"
# 如果未提供,模型将从 Hugging Face 模型中心下载
# 取消注释以下行以指定本地文件系统中的模型路径
# path = "the-model-path-in-the-local-file-system"
[[models.embeddings]]
name = "BAAI/bge-large-zh-v1.5"
provider = "hf"
# 如果未提供,模型将从 Hugging Face 模型中心下载
# 取消注释以下行以指定本地文件系统中的模型路径
# path = "the-model-path-in-the-local-file-system"
2. 数据集与数据库准备
在开始分析之前,需要获取 Superstore 数据集并将其导入数据库中。您可以从以下链接下载数据集:
数据集网址:https://www.kaggle.com/datasets/jr2ngb/superstore-data
本案例使用MySQL数据库进行演示,具体步骤如下:
- 首先确保您已安装MySQL数据库并启动服务
- 创建数据库:
CREATE DATABASE superstore;
USE superstore; - 创建
superstore_dataset表:CREATE TABLE `superstore_dataset` (
`row_id` int NOT NULL COMMENT 'Unique ID for each row',
`order_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Unique Order ID for each Customer.',
`order_date` date NULL DEFAULT NULL COMMENT 'Order Date of the product.',
`ship_date` date NULL DEFAULT NULL COMMENT 'Shipping Date of the Product.',
`ship_mode` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Shipping Mode specified by the Customer.',
`customer_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Unique ID to identify each Customer.',
`customer_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Name of the Customer.',
`segment` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'The segment where the Customer belongs.',
`country` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT ' Country of residence of the Customer.',
`city` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'city where the customer lives.',
`state` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'State of residence of the Customer.',
`postal_code` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Postal Code of every Customer.',
`region` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Region where the Customer belong.',
`market` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'market name',
`product_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Unique ID of the Product.',
`category` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Category of the product ordered.',
`sub_category` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Sub-Category of the product ordered.',
`product_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'Name of the Product',
`sales` float(10, 2) NULL DEFAULT NULL COMMENT 'Product sales price',
`quantity` int NULL DEFAULT NULL COMMENT 'Quantity of the Product.',
`discount` float(10, 3) NULL DEFAULT NULL COMMENT 'Discount provided.',
`profit` float(10, 4) NULL DEFAULT NULL COMMENT 'Profit/Loss incurred.',
`shipping_cost` float(10, 2) NULL DEFAULT NULL COMMENT 'shipping cost',
`order_priority` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT 'order priority',
PRIMARY KEY (`row_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic; - 将下载的数据导入到表中
3. 知识库准备
数据分析多智能体应用需要业务相关的知识文件来描述 Superstore 数据集的指标信息,包括指标名、计算规则、字段等。创建指标.txt文本文件来描述 Superstore 业务指标,不同指标的描述可用"###"分隔,方便后续分片处理。针对当前案例设置两个指标:订单数量和订单占比。
###
指标名称:订单数量
字段:quantity
计算规则:无
建议计算维度�:地区(region)
阈值:0.01
###
指标名称:订单占比
字段:quantity
计算规则:SUM(quantity) / TOTAL(SUM(quantity)) OVER()
建议计算维度:地区(region)
阈值:0.05
4. 数据分析
使用配置文件启动 DB-GPT 服务:
# 使用 OpenAI 代理模型配置启动
uv run dbgpt start webserver --config configs/dbgpt-proxy-openai.toml
# 或使用本地模型配置启动
uv run dbgpt start webserver --config configs/dbgpt-local-glm.toml
打开浏览器并访问:http://localhost:5670
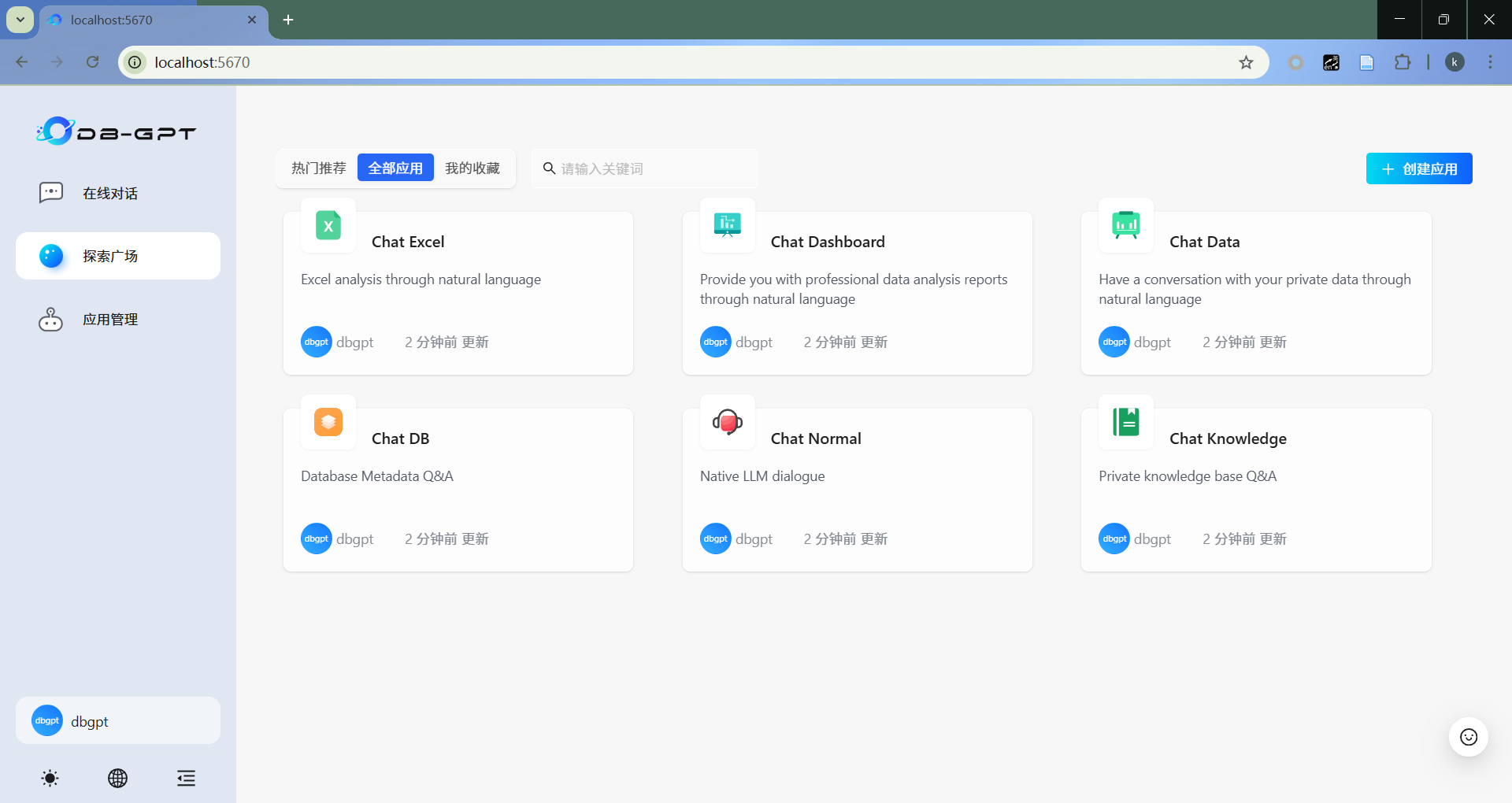
4.1 知识库接入
- 选择知识库
点击“应用管理”,选择“知识库”
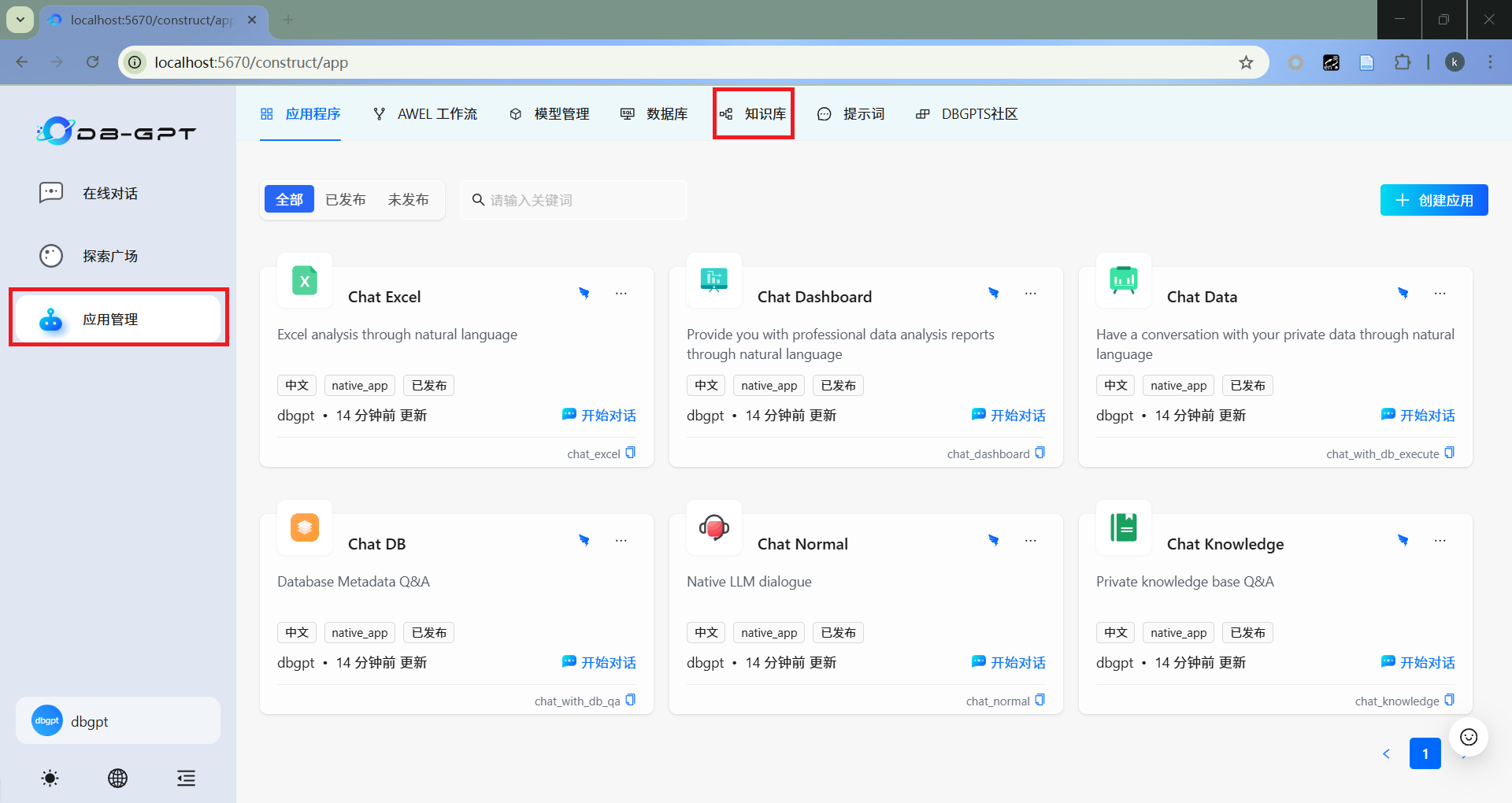
- 创建知识库
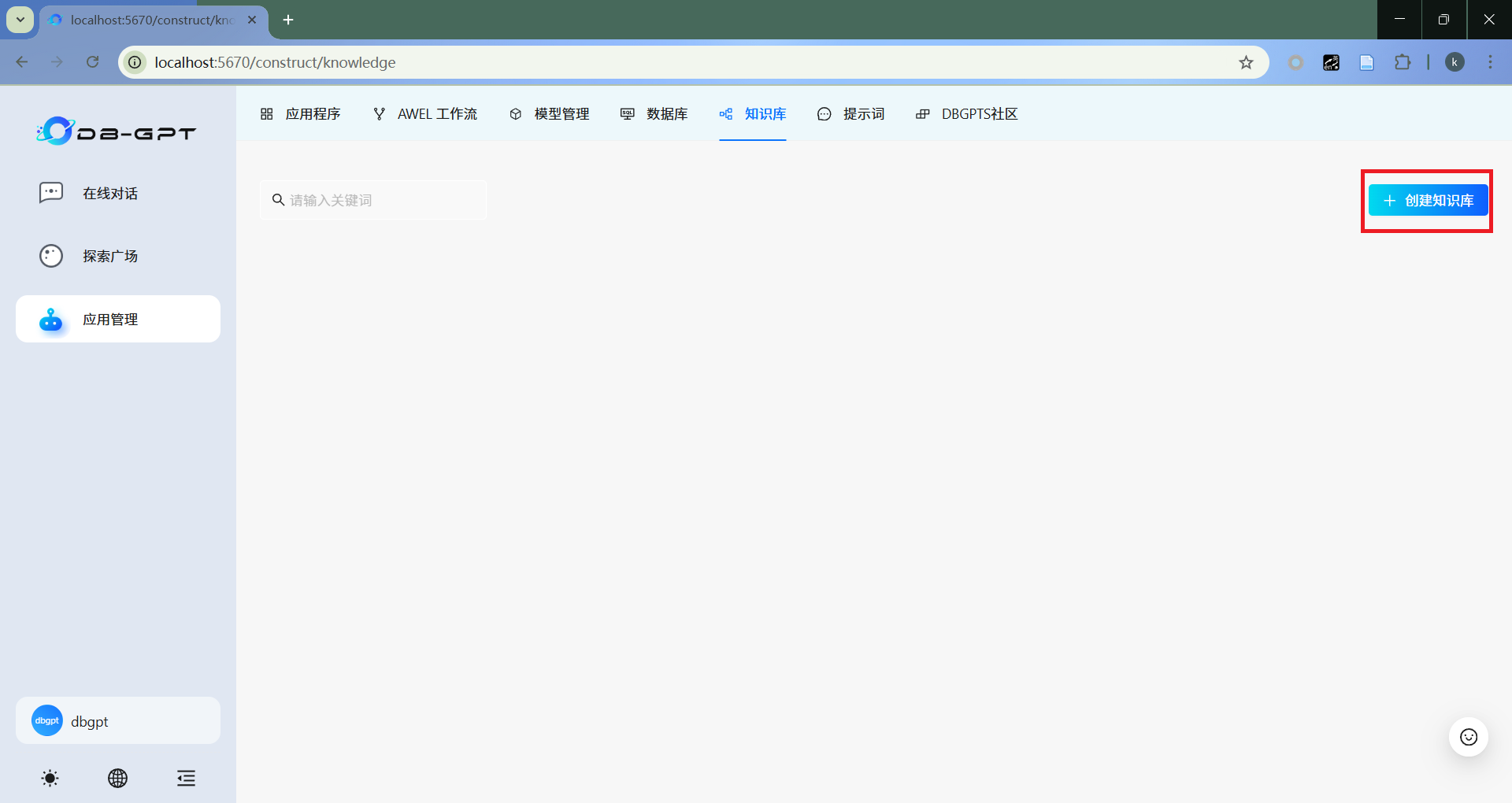
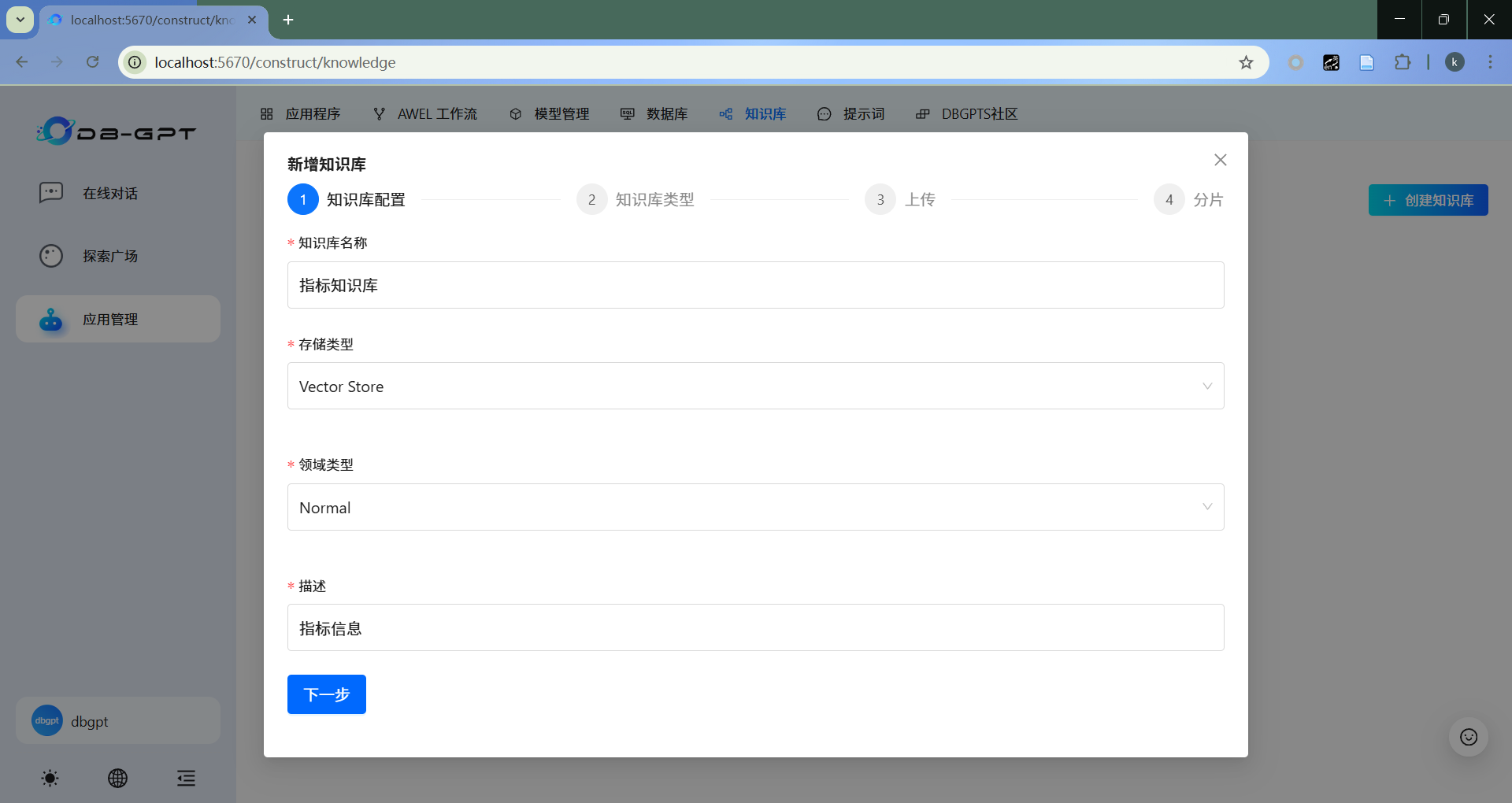
- 知识库配置
填写相关配置信息。
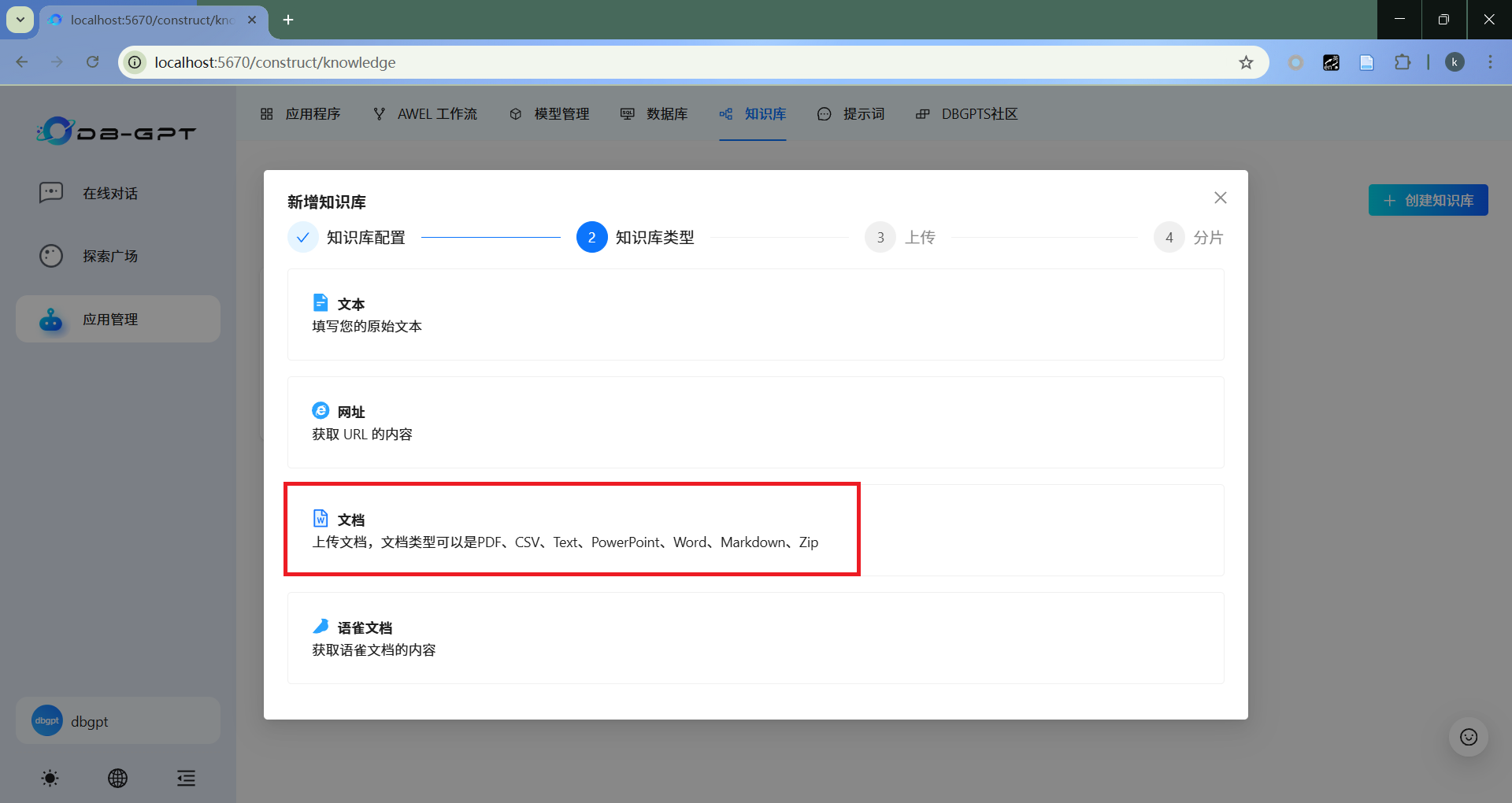
- 知识库类型
此处选择文档。
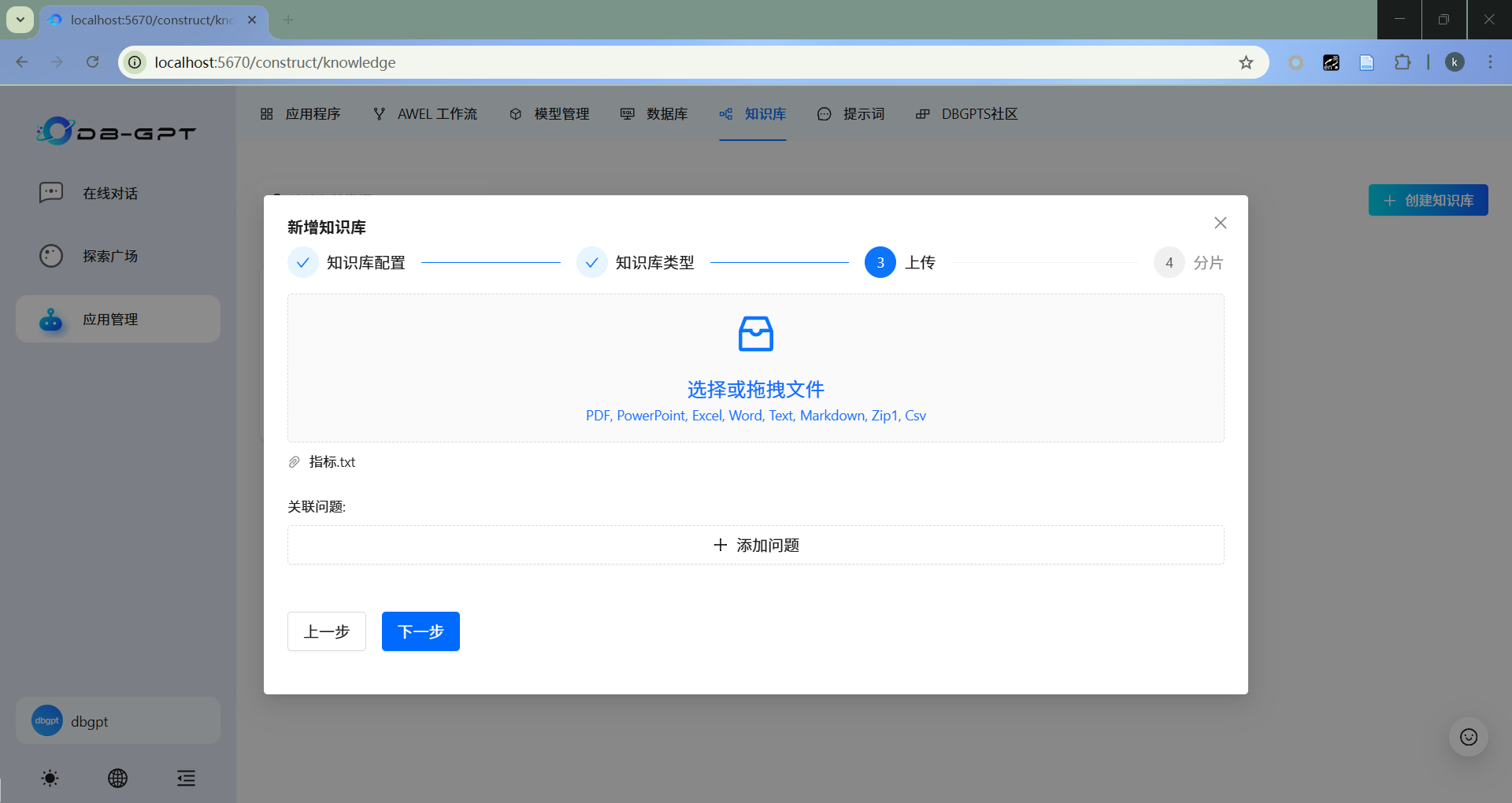
- 上传
此处上传提前准备好的指标.txt文档。
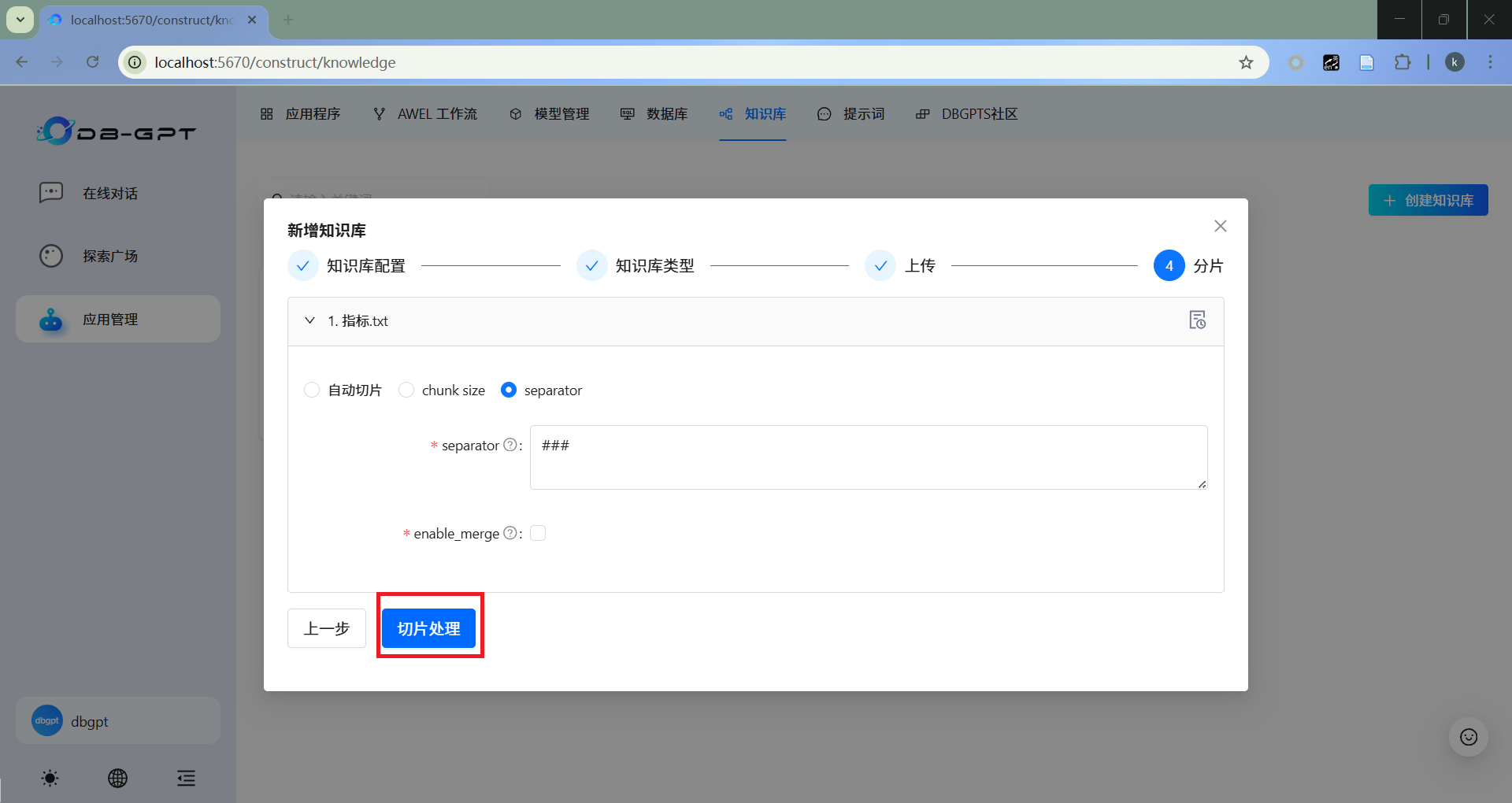
- 分片
分片策略选择"separator",分隔符设置为"###"。
- 成功创建知识库
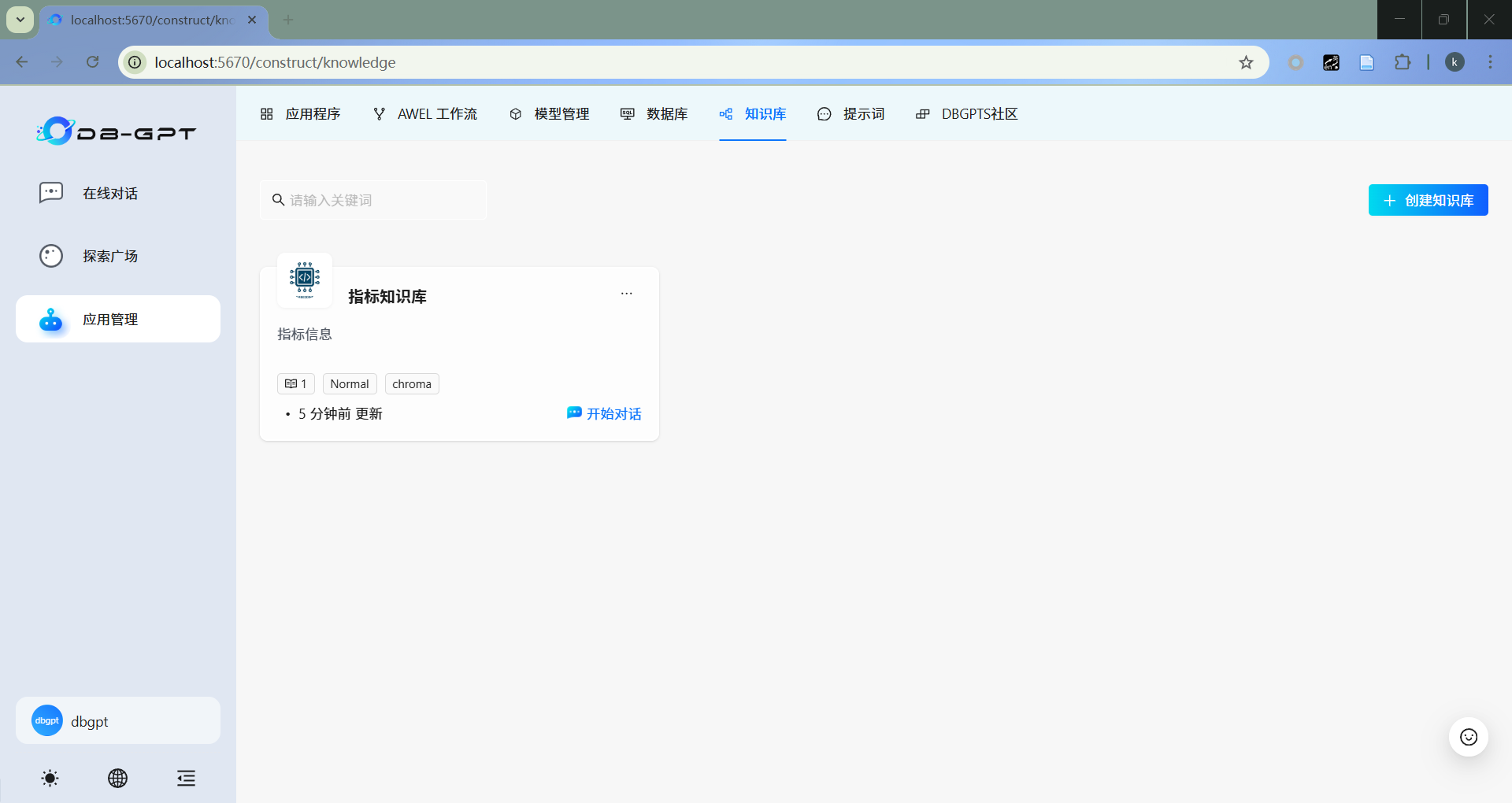
4.2 创建数据库
- 选择数据库
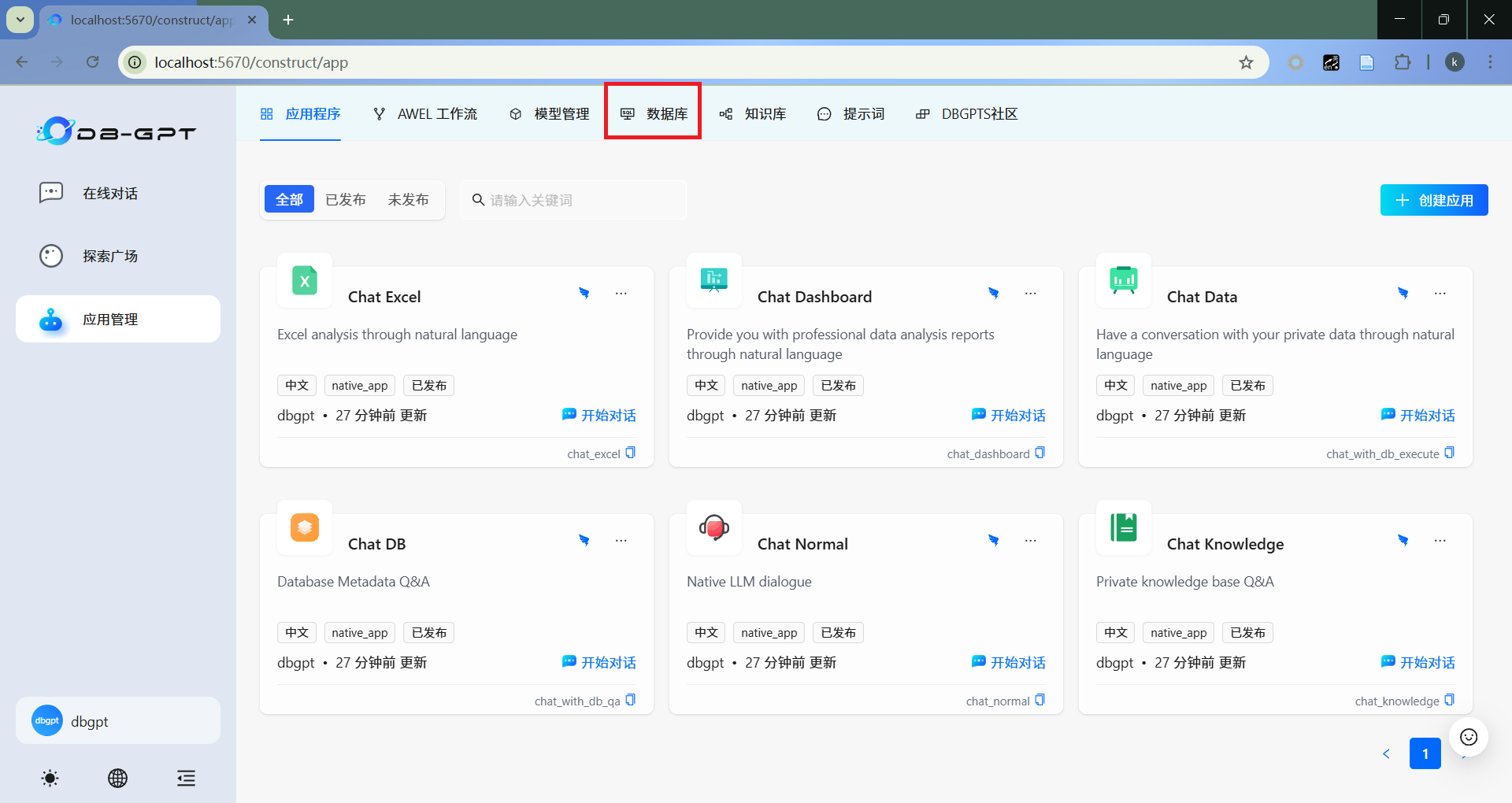
- 添加数据源
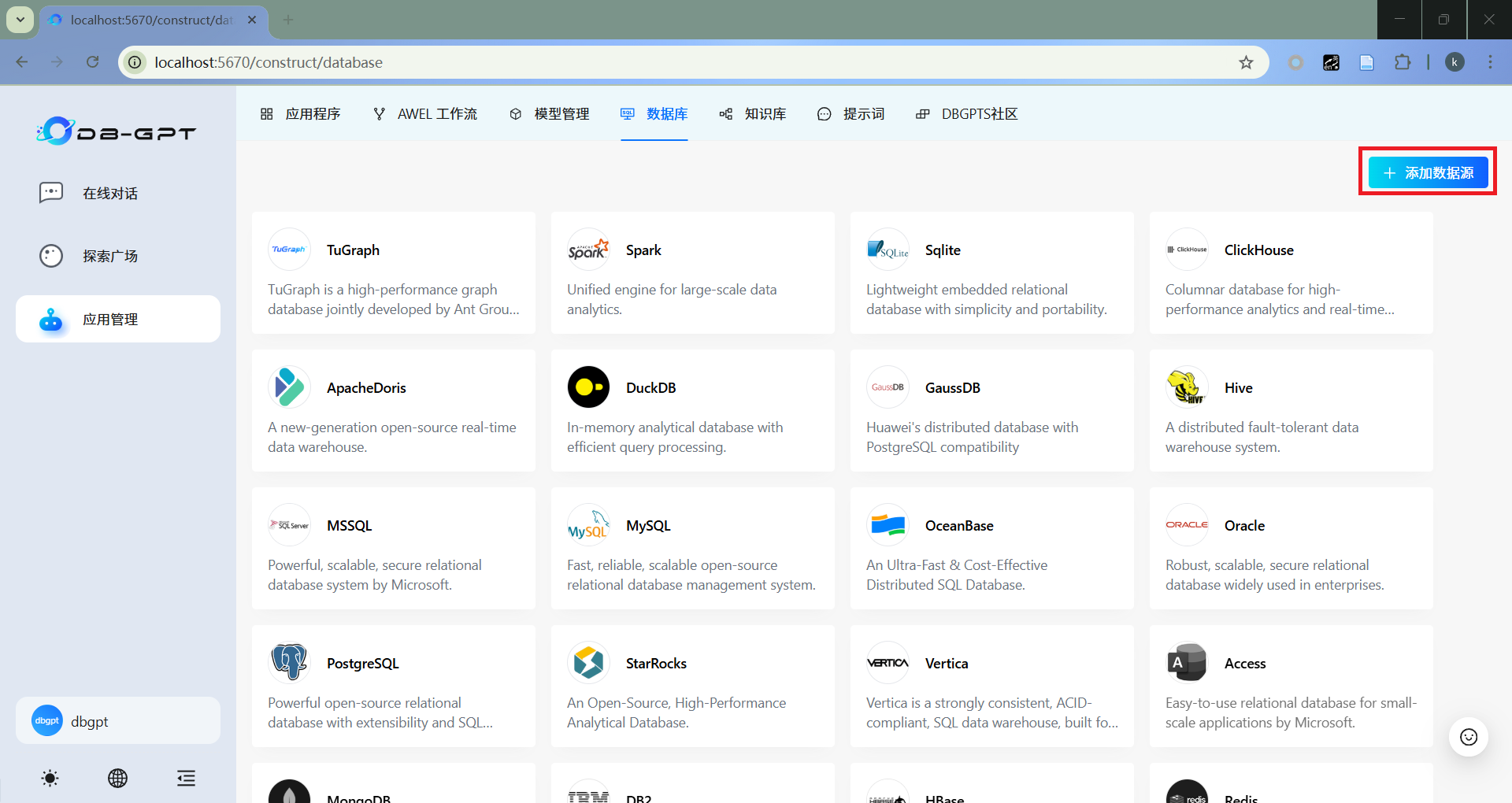
- 配置数据源
配置准备好的数据库连接信息。
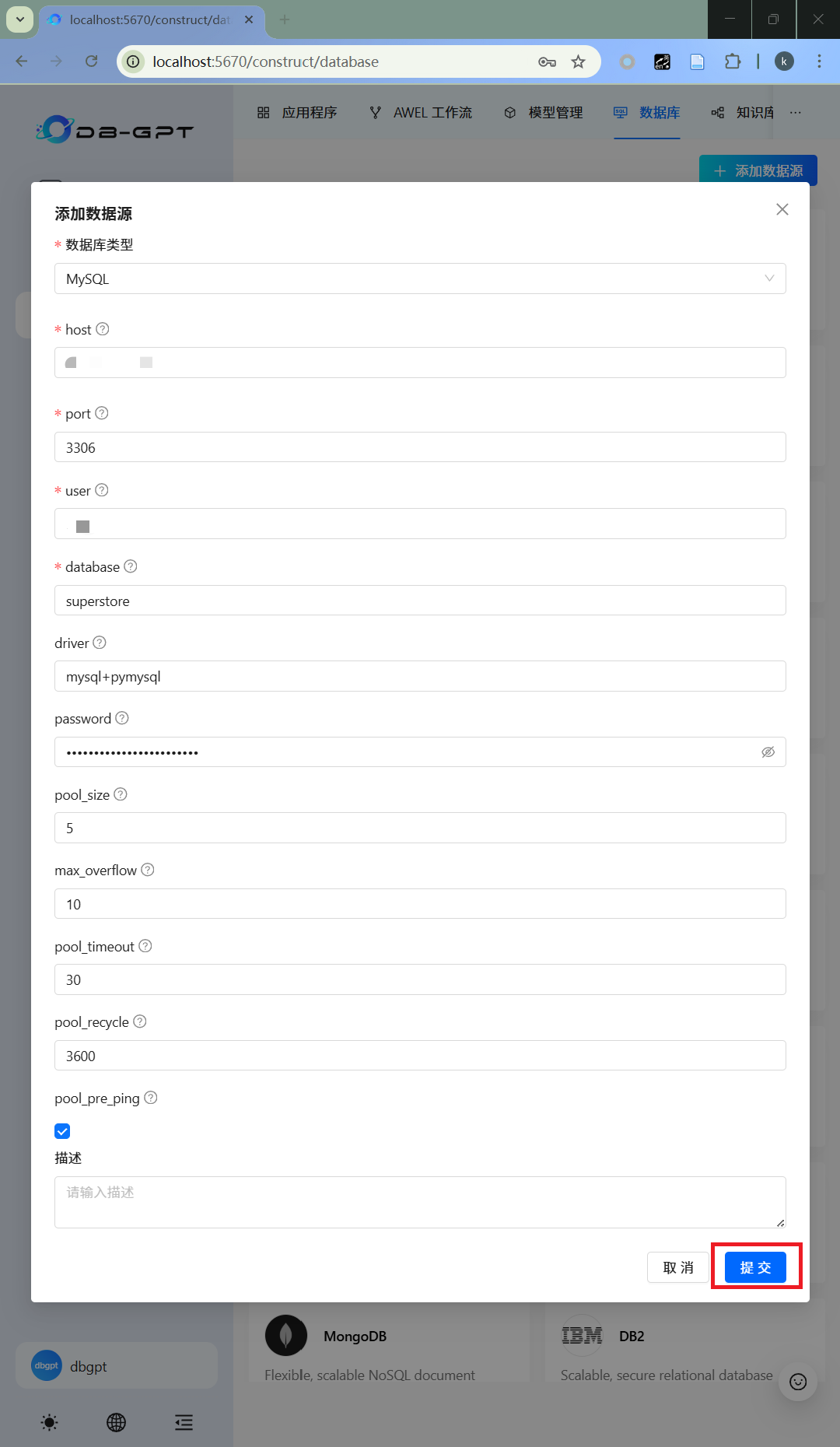
- 添加成功
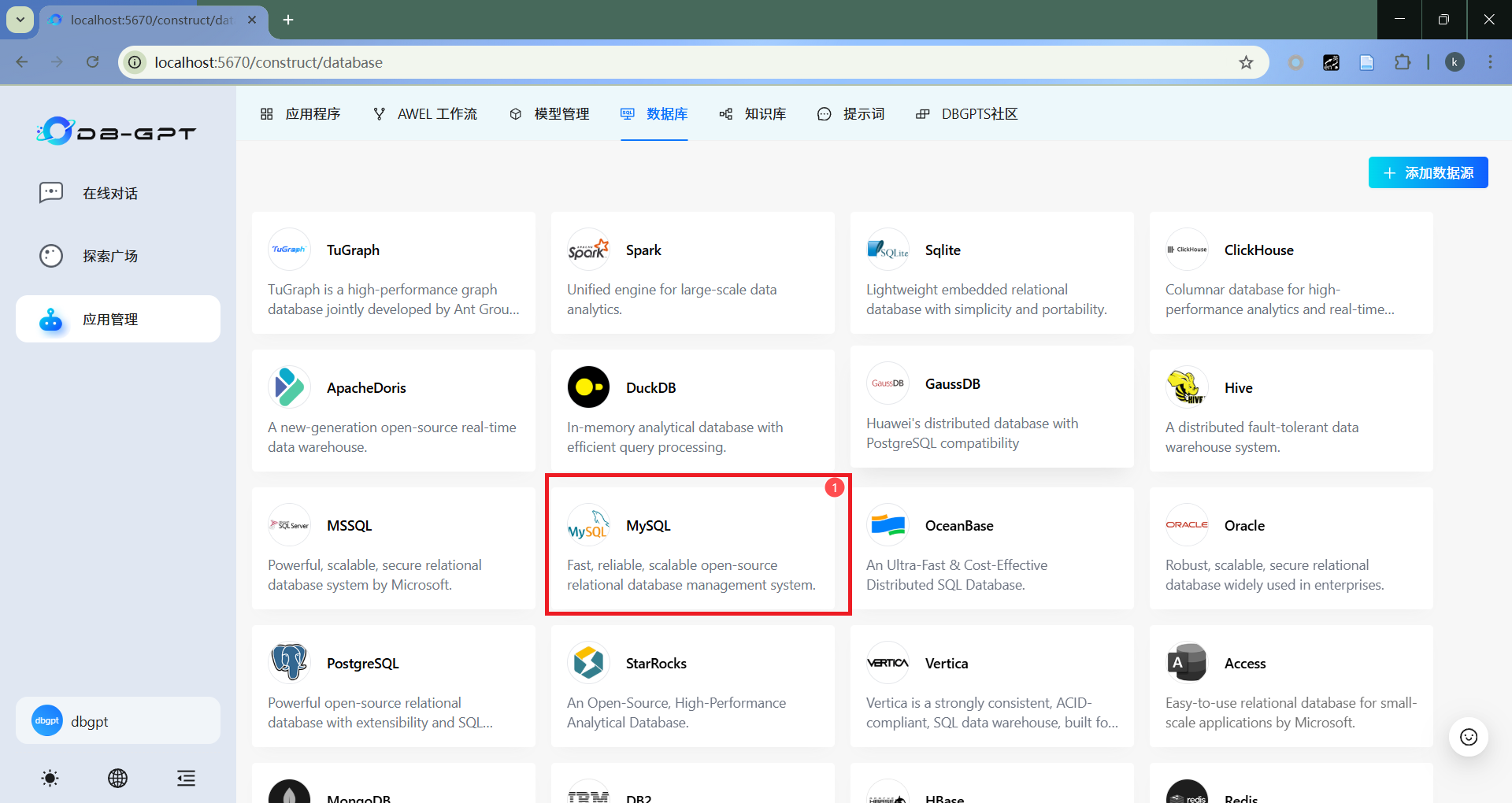
4.3 创建数据分析应用
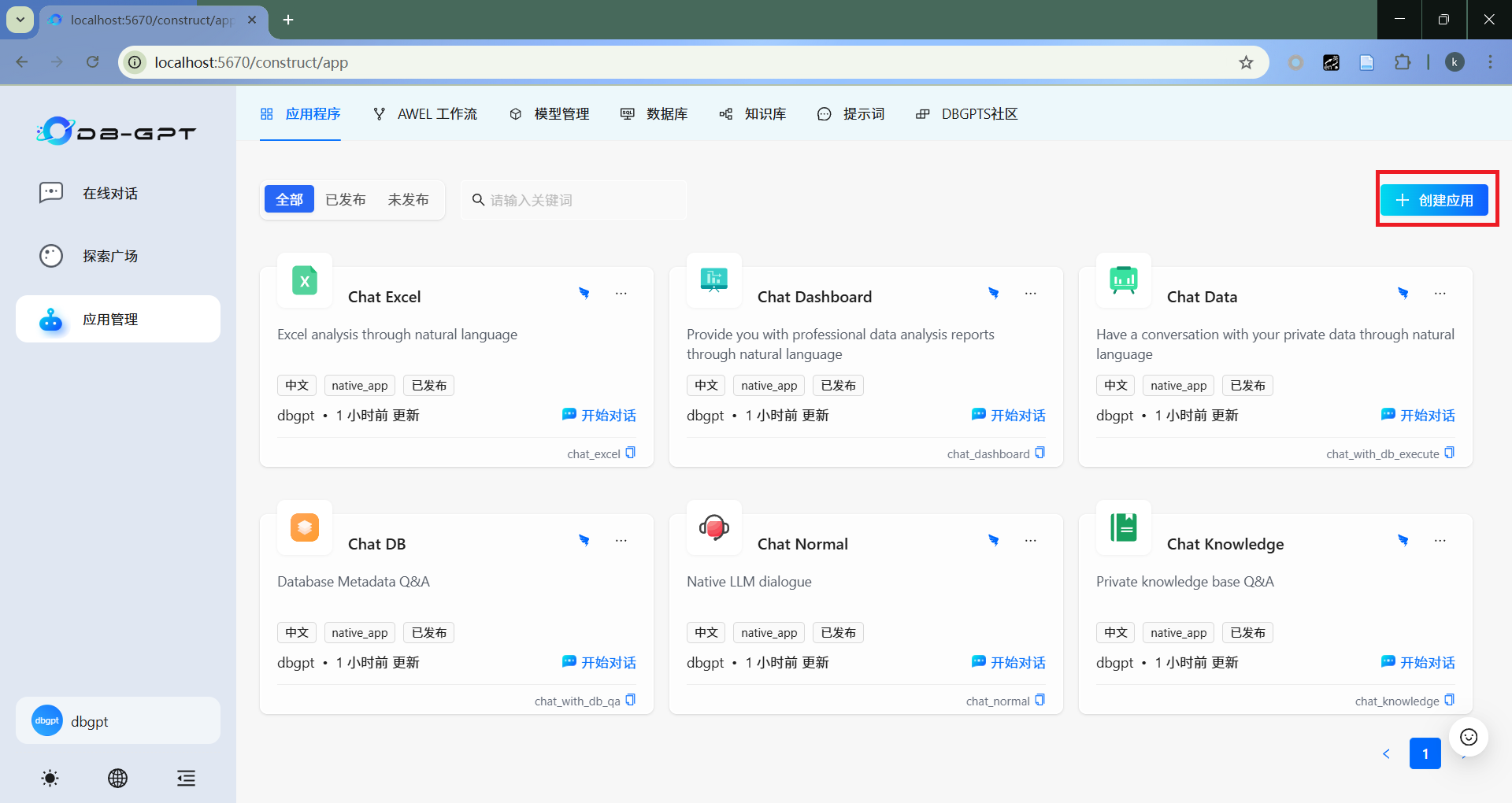
- 创建应用
点击“创建应用”
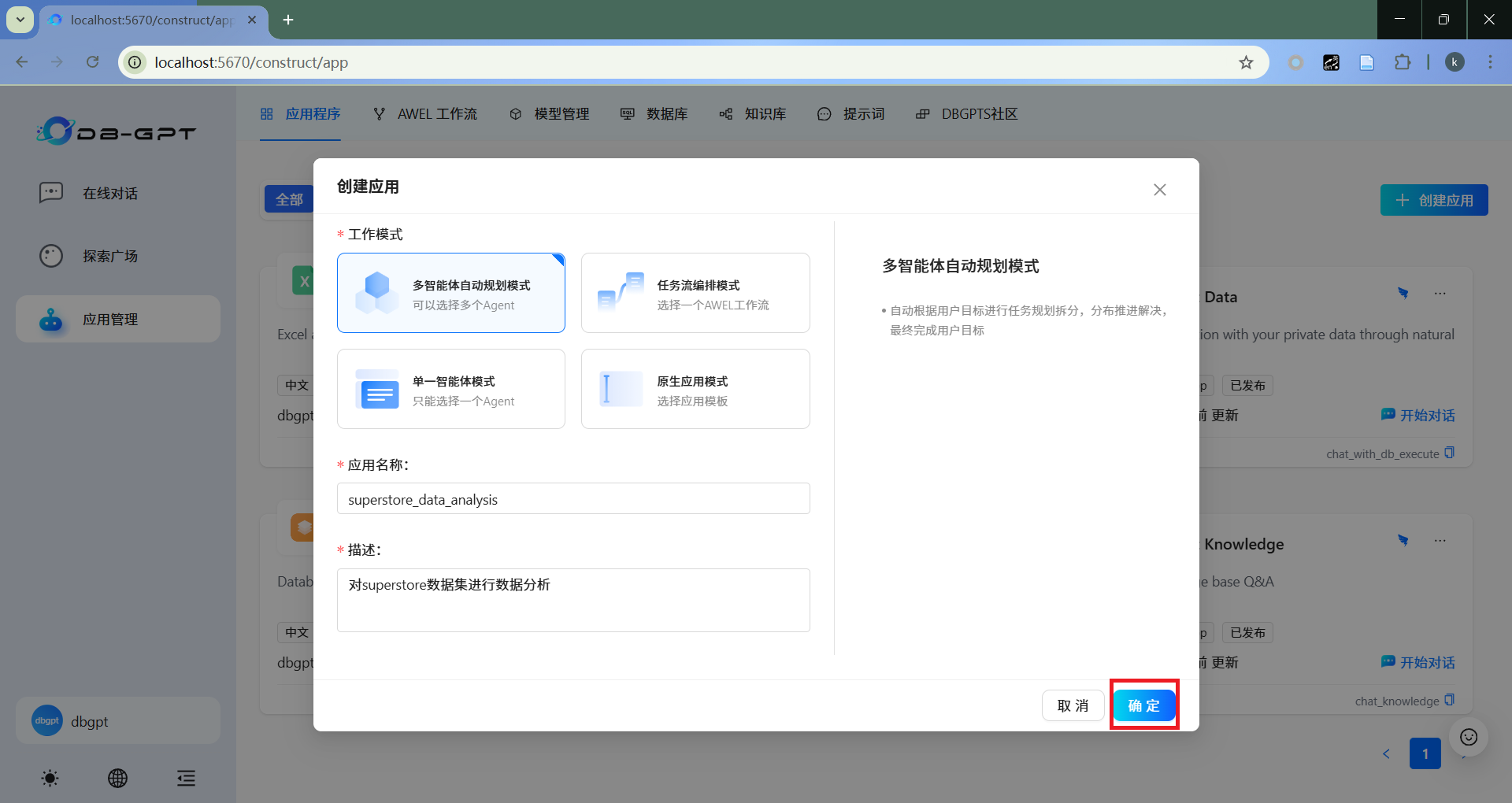
- 基础配置
选择“多智能体自动规划模式”,并输入应用名称和对应描述。
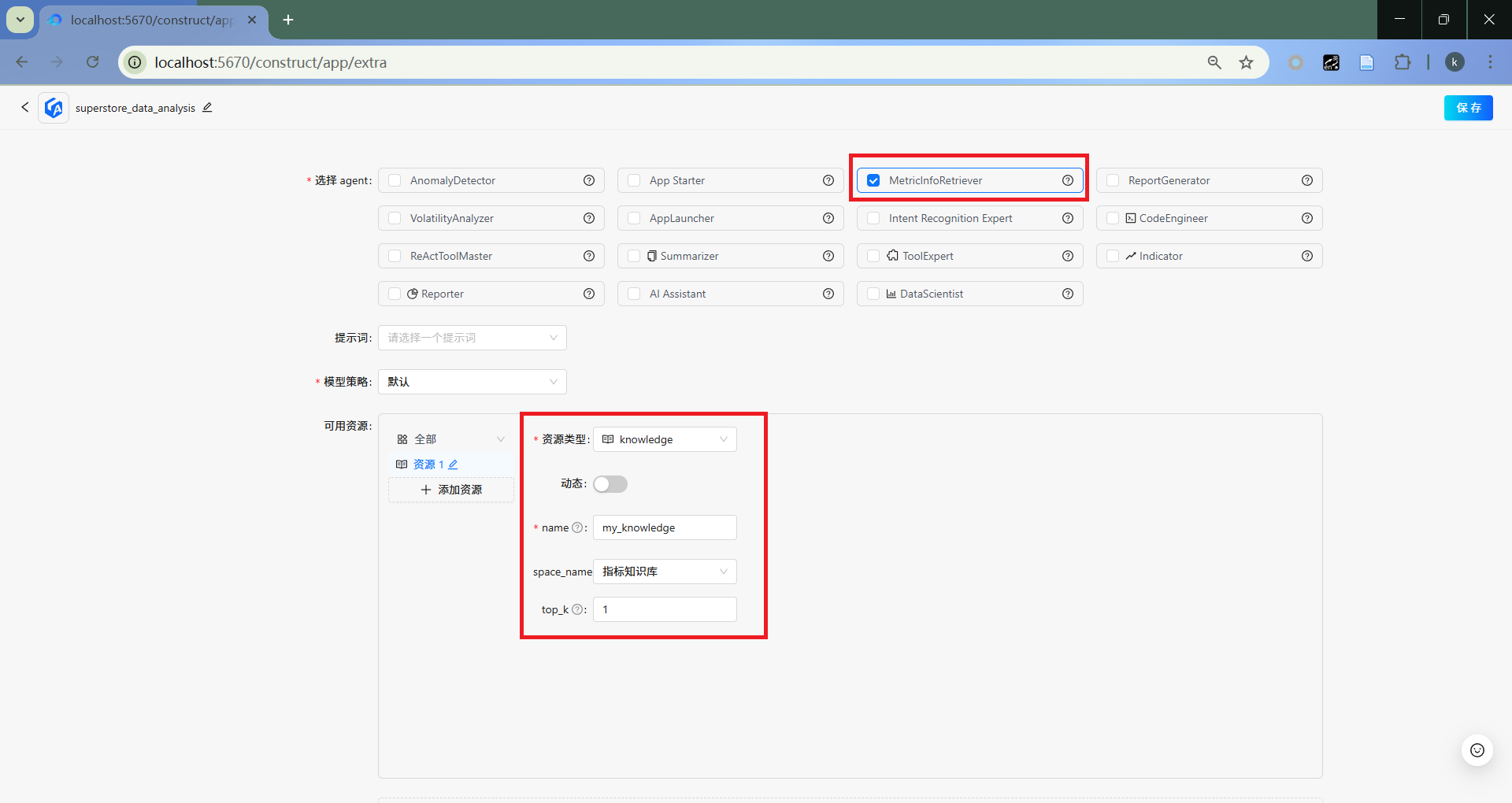
- 加入
MetricInfoRetriever
选取MetricInfoRetriever,并配置知识库资源。
- 加入
DataScientist
选取DataScientist,并配置数据库资源。
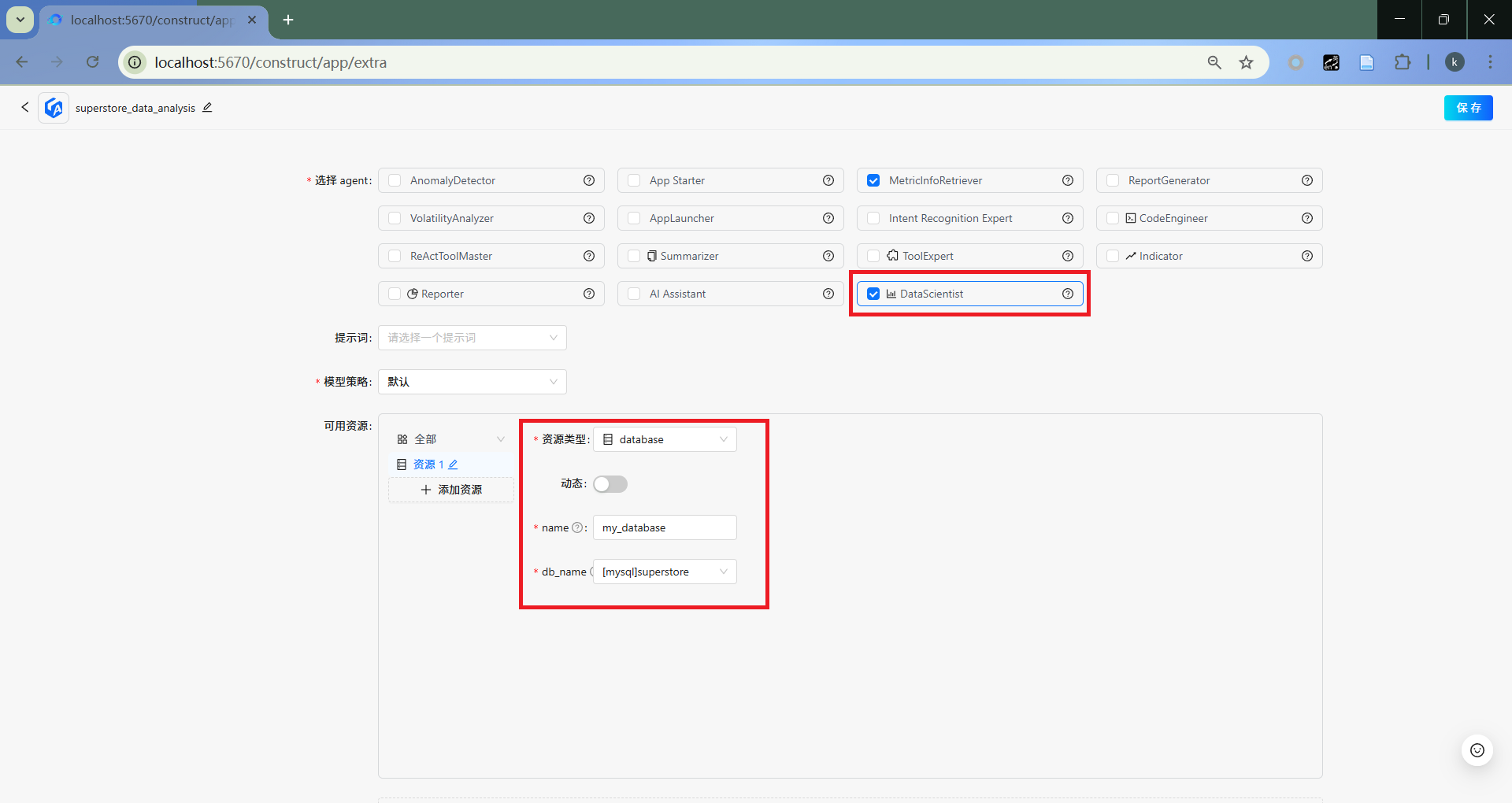
- 加入
AnomalyDetector
选取AnomalyDetector。
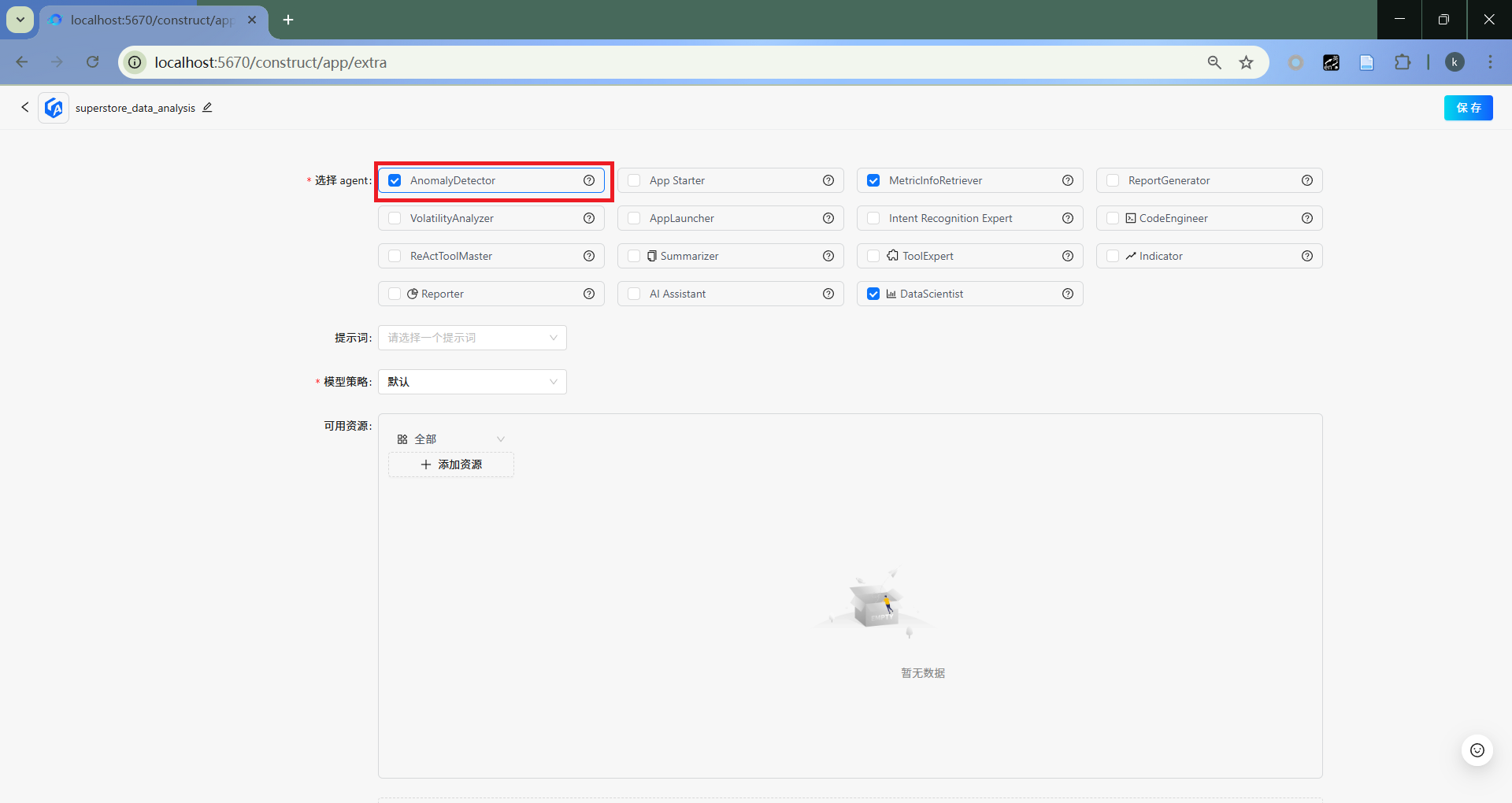
- 加入
VolatilityAnalyzer
选取VolatilityAnalyzer,并配置数据库资源。
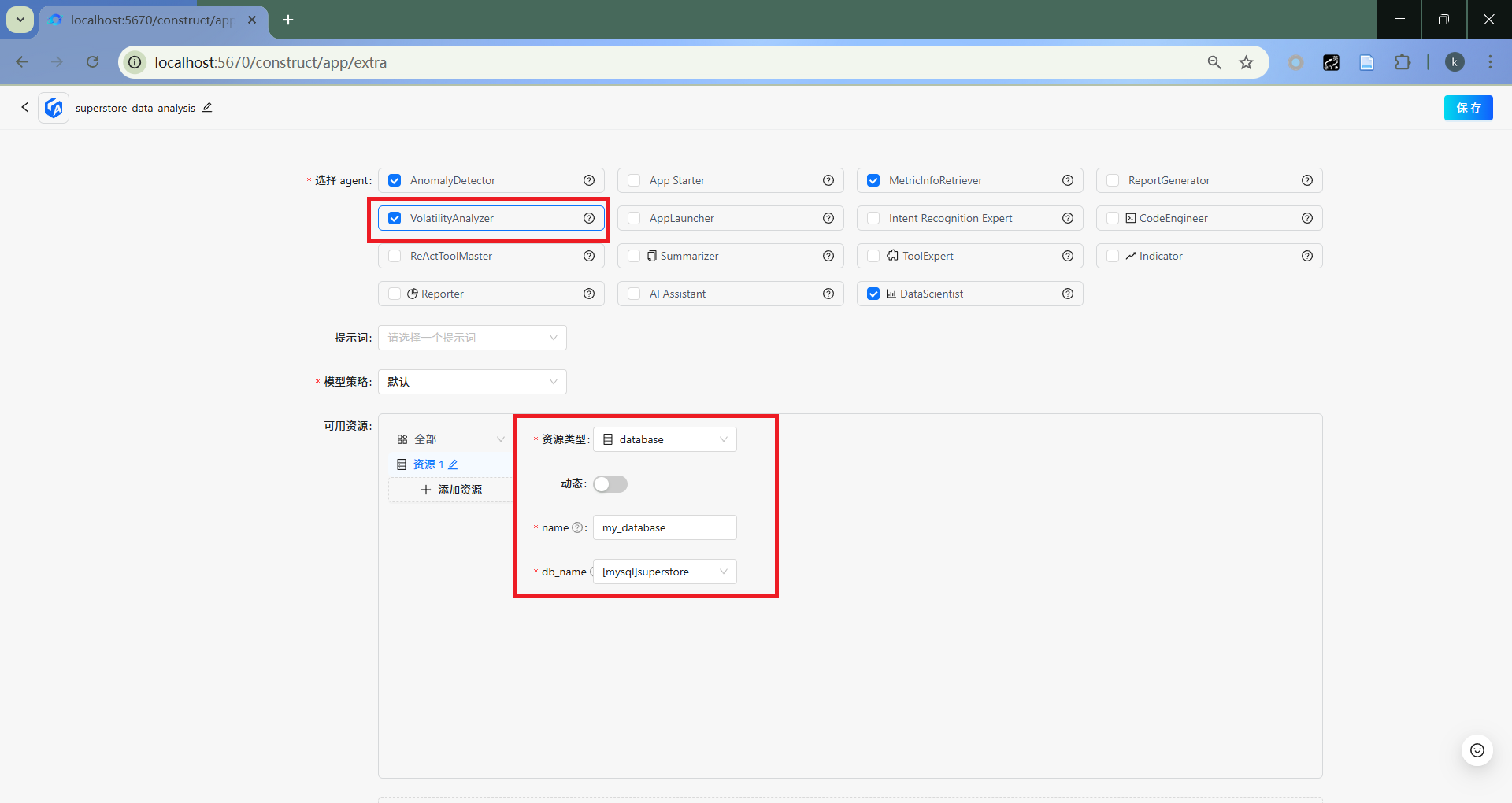
- 加入
ReportGenerator
选取ReportGenerator。
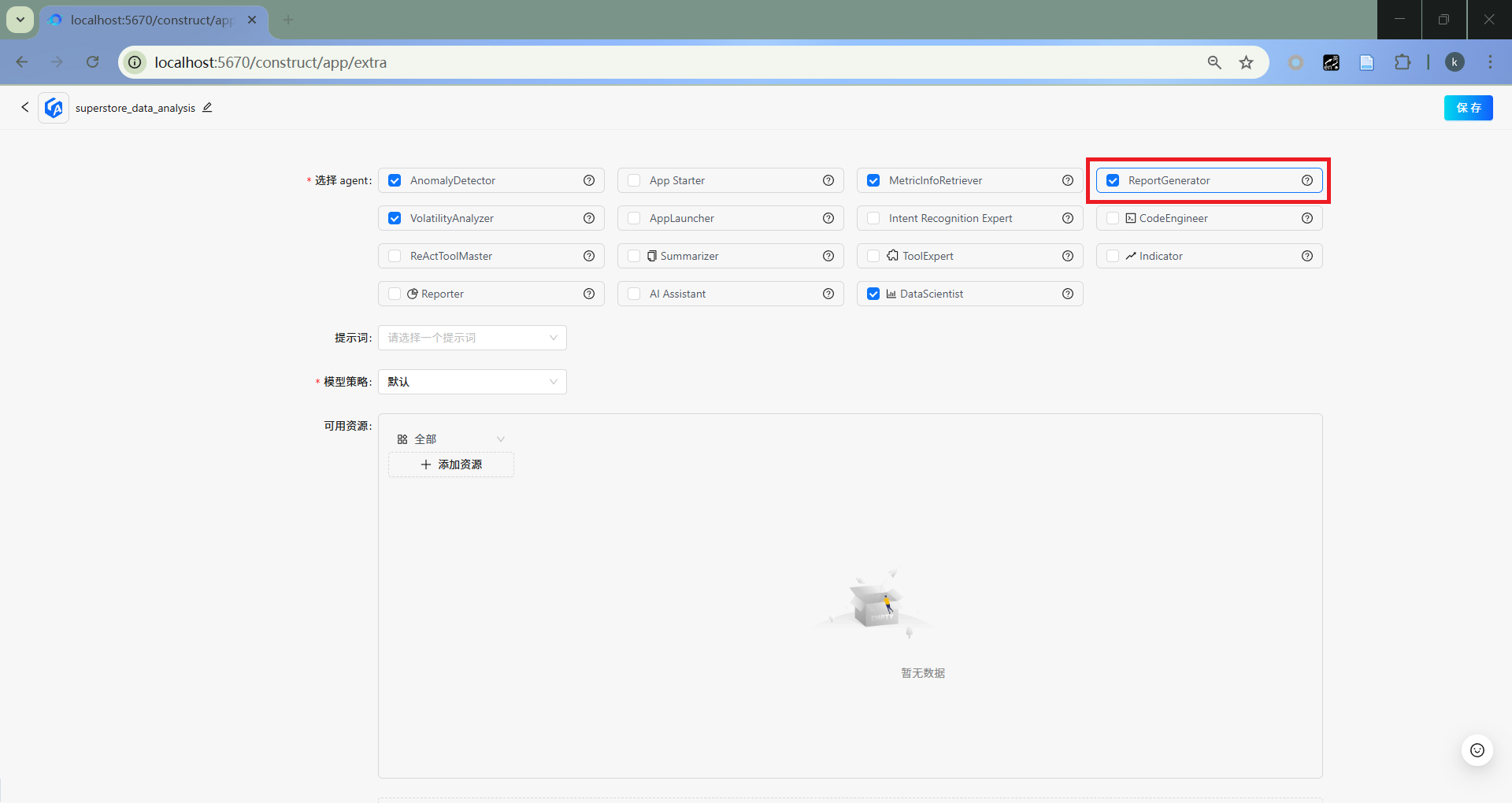
- 保存
点击“保存”。
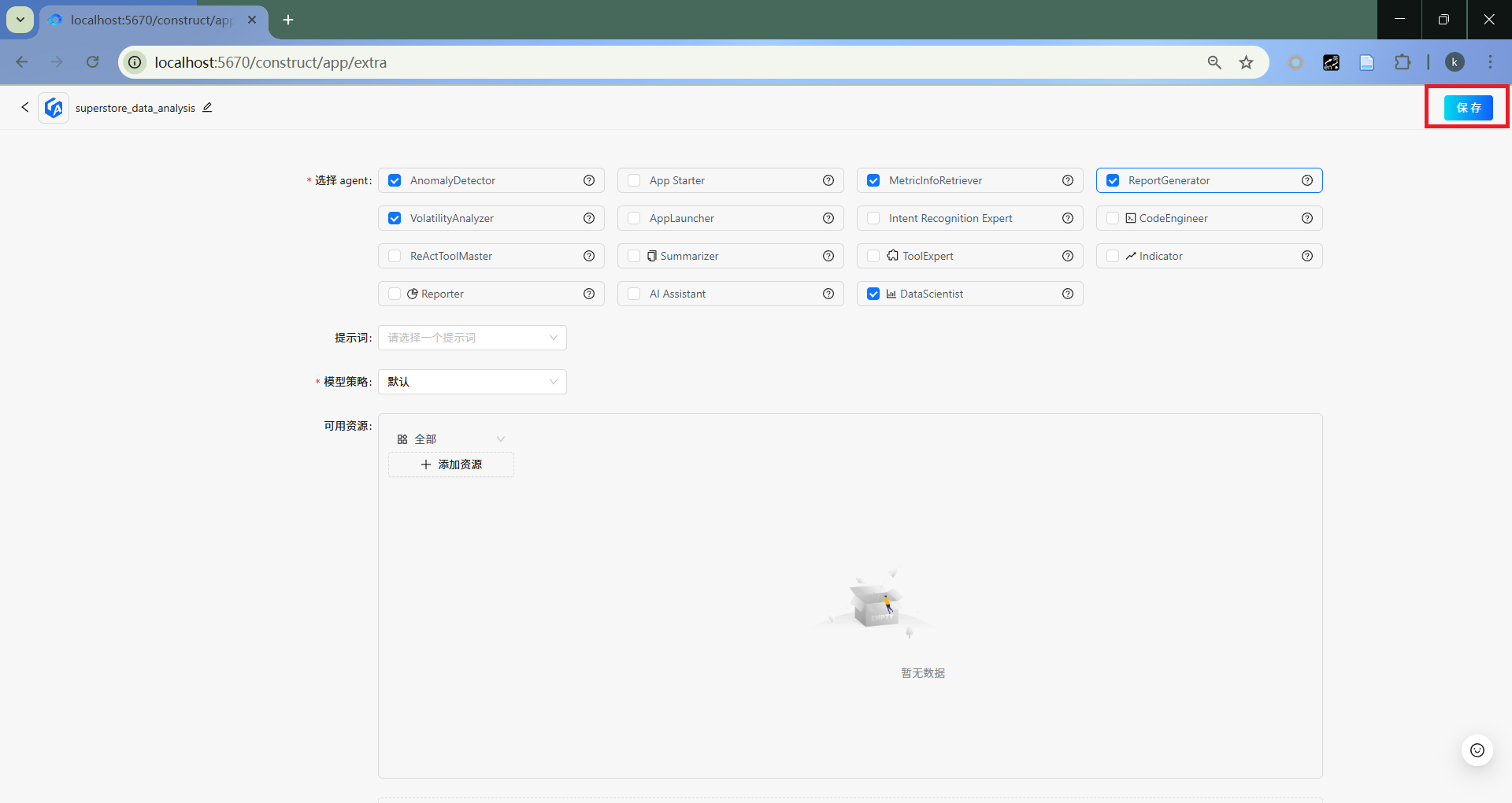
4.4 使用
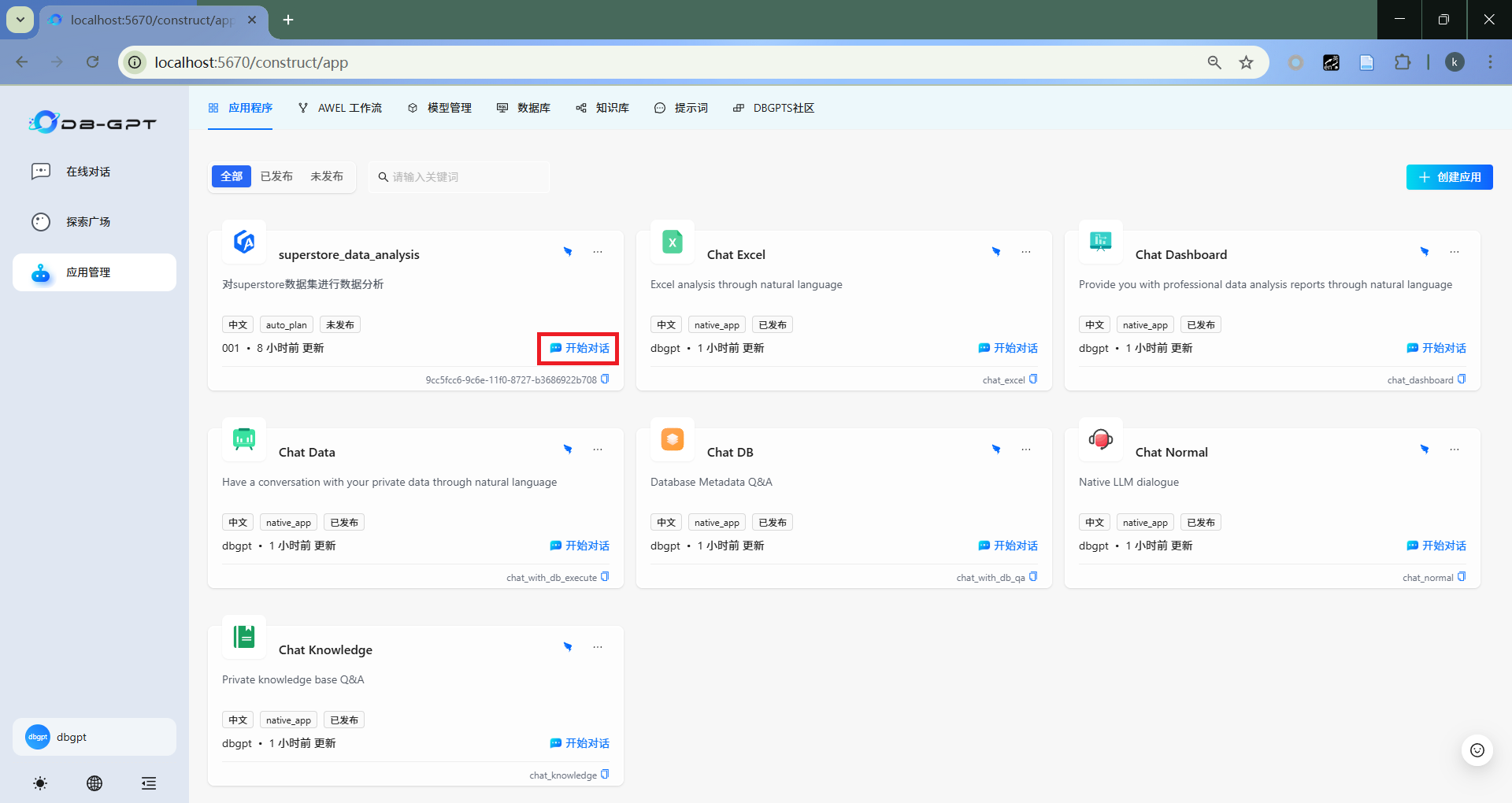
- 开始对话
点击“开始对话”。
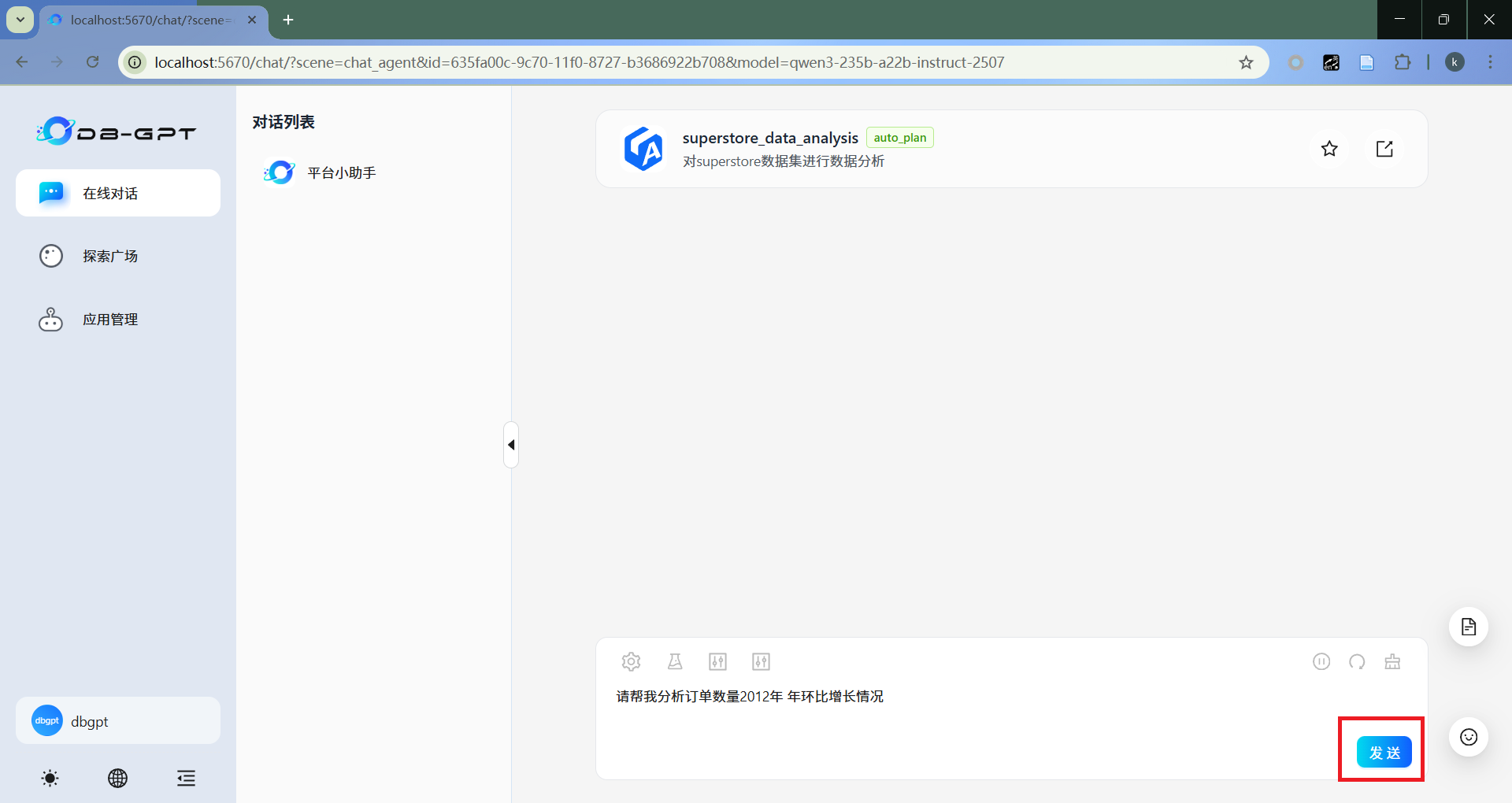
- 提问
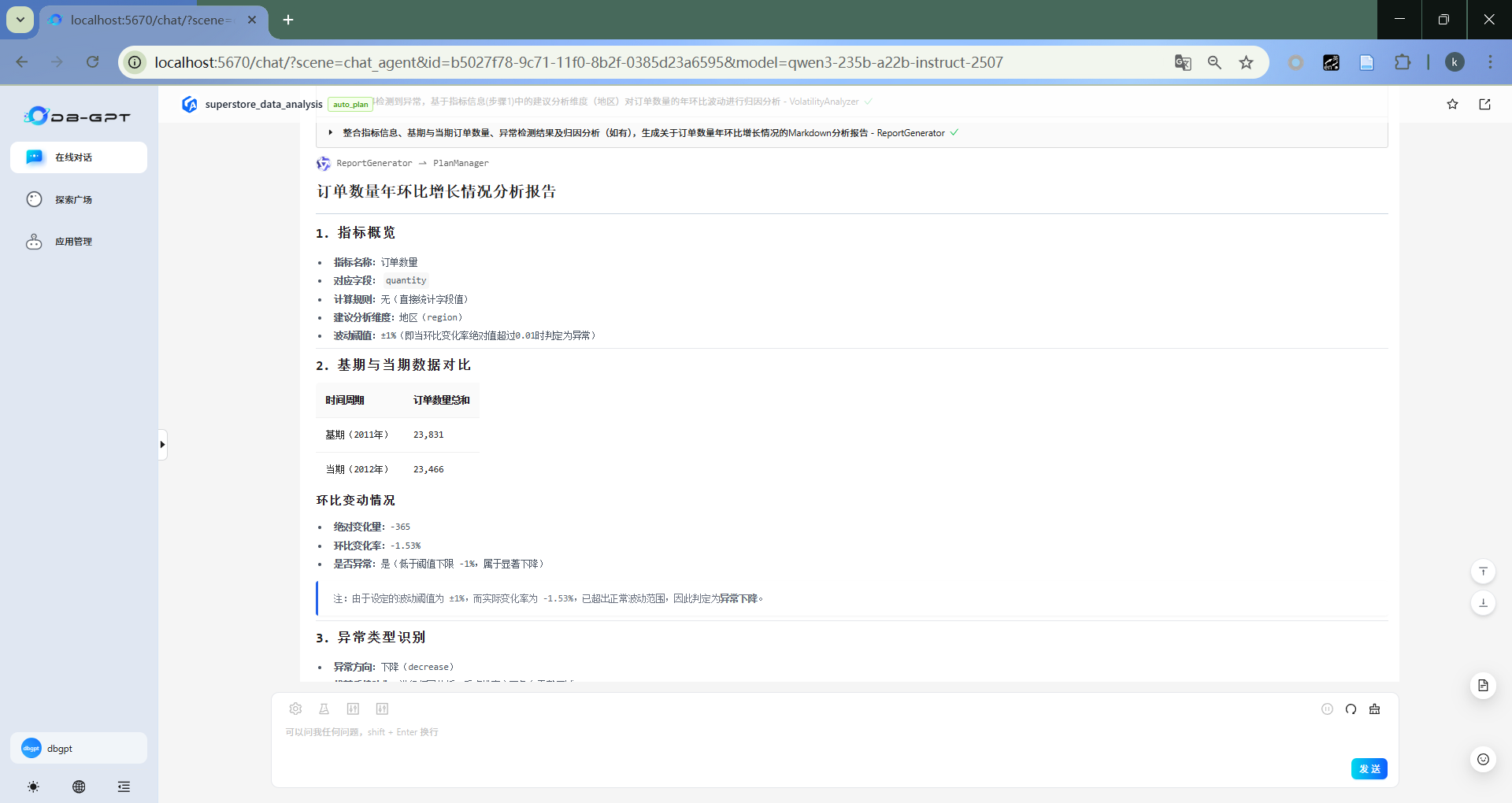
在输入框中输入问题,如“请帮我分析订单数量2012年 年环比增长情况”,点击发送。
- 回答
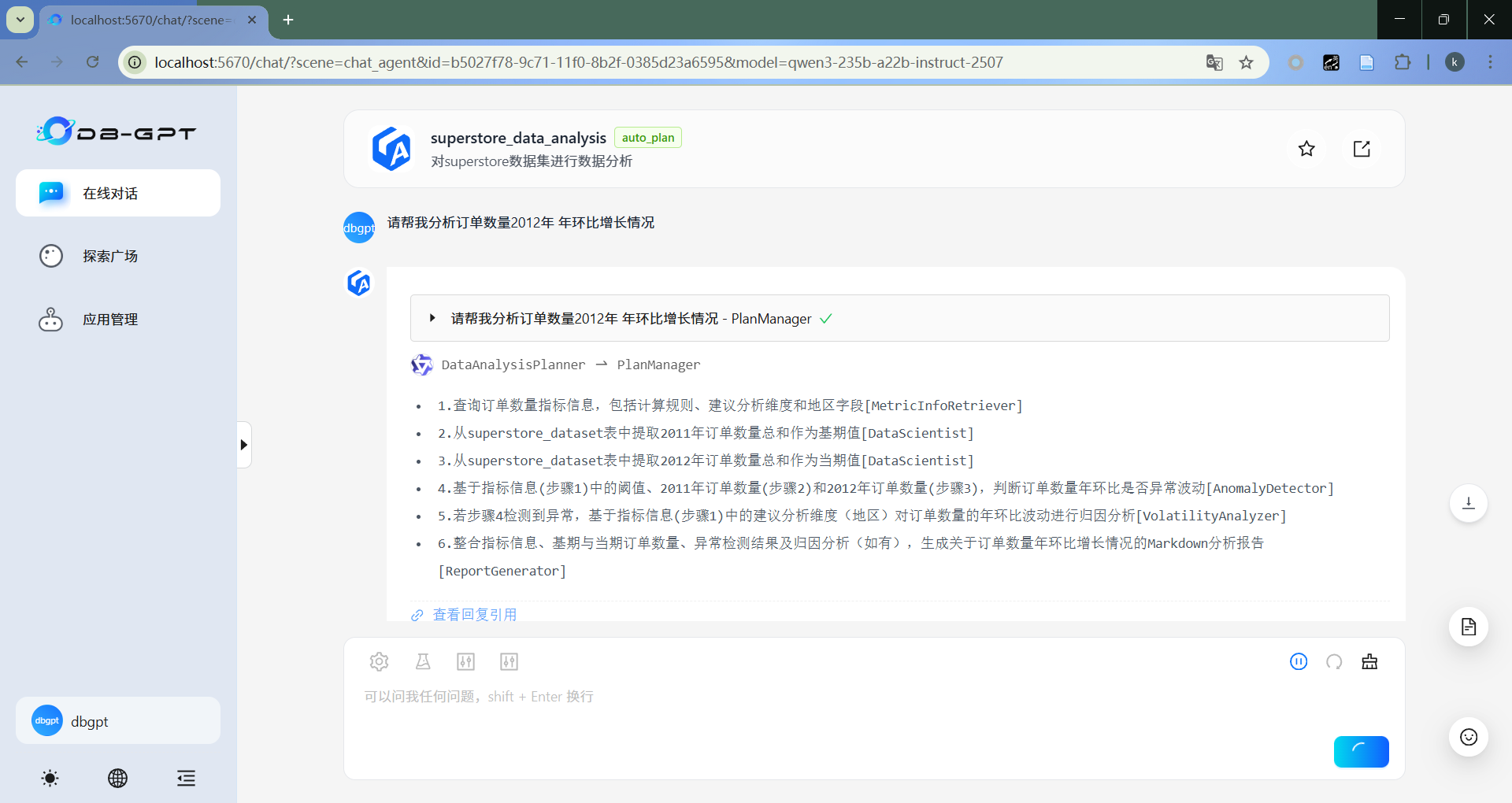
- 报告生成
最终生成分析报告。