Ant Group Data Retrieval Benchmark Dataset Guide
For Text2SQL tasks, we provide a dataset benchmarking capability. It evaluates different large language models (LLMs) and agents on Text2SQL, covering syntax correctness, semantic accuracy, and execution validity. It outputs metrics such as executability rate and accuracy rate, and provides an evaluation report.
- Open-source Text2SQL dataset repository by Ant Group: Falcon
- DB-GPT supports LLM evaluation based on the Falcon benchmark dataset
Introduction
To objectively and fairly evaluate models on Text2SQL tasks, we provide a benchmarking module and dataset. This module supports comprehensive evaluation of all models in the DB-GPT framework and provides an evaluation report.
The benchmark dataset used by the module, Falcon, is a high-quality and evolving open-source Text2SQL dataset from Ant Group. The dataset aims to stress-test models in complex, cross-domain analysis scenarios, with a focus on:
- SQL computation challenges — multi-table joins, nested CTEs, window functions, ranking, type casting, regex filters...
- Language challenges — Chinese fuzzy time expressions, colloquial business terms, ellipsis, multi-intent questions...
The benchmark includes 28 datasets and 90 tables. As of now, 500 Chinese questions of varying difficulty have been officially released.
Among them: easy: 151, medium: 130, hard: 219.
Core Features Of Benchmark Dataset
- ✅ Multi-dimensional evaluation: three-layer checks on syntax correctness, semantic accuracy, and execution validity
- 🧠 Dynamic difficulty levels: 500 Chinese questions from Kaggle datasets (various difficulties), covering multi-step reasoning, complex nested queries, and advanced SQL features
- ✍️ Detailed schema annotations: rich schema information including data types, natural language aliases, table relations, and sample data, helping models understand database structures
- 🌐 Real-world scenario modeling: more ambiguous language expressions and more questions collected from Ant Group’s real production scenarios (in preparation)
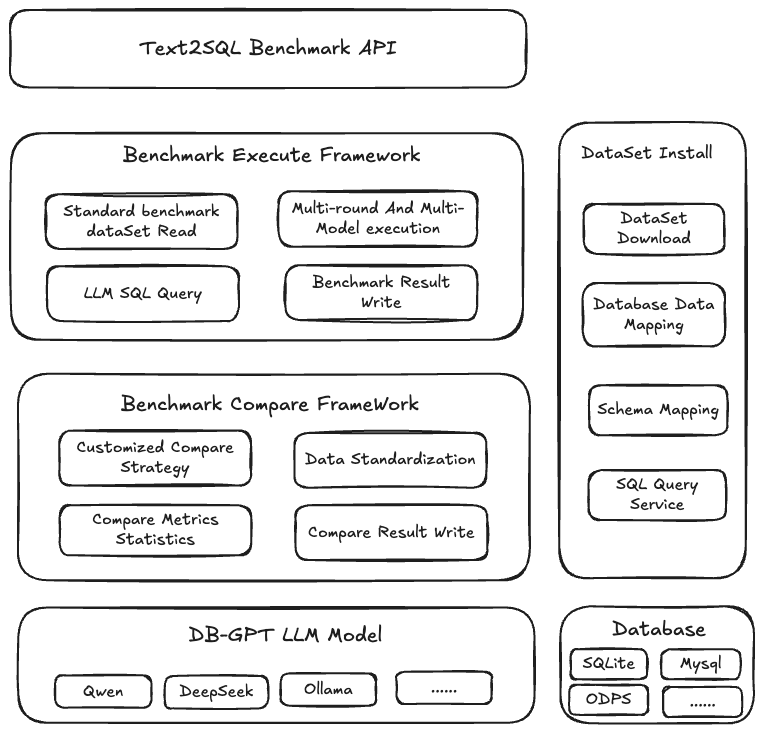
System Design
Core capabilities of the benchmarking module:
- Text2SQL evaluation API: provide APIs to create evaluation tasks
- Benchmark execution framework: run Text2SQL tasks based on the benchmark questions
- Result comparison framework: compare results between the standard answers and LLM-generated SQL, and aggregate the evaluation results
- Dataset installation and database mapping: install the benchmark dataset and map data into the database to provide LLM SQL query service
Evaluation Metrics
| Metric | Formula | Description |
|---|---|---|
| Executability Rate | Number of syntactically correct samples / Total samples | The proportion of SQL statements generated by the model that are syntactically correct and can execute correctly in the database |
| Accuracy Rate | Number of semantically correct samples / Total samples | The proportion of SQL statements generated by the model that are syntactically correct, execute correctly in the database, and are semantically correct |
Dataset Structure
Standard Benchmark Structure
| Field | Description | example |
|---|---|---|
| 编号 | Question serial number | 1, 2... |
| 数据集ID | Dataset ID | D2025050900161503000025249569, ... |
| 用户问题 | Question title | 各性别的平均年龄是多少,并按年龄顺序显示结果? |
| 自定义标签 | Question source, SQL type | KAGGLE_DS_1, CTE1 |
| 知识 | Knowledge context required | 暂无 |
| 标准答案SQL | Correct SQL for the question(based on Alibaba Cloud MaxCompute syntax) | SELECT gender, AVG(age) AS avg_age FROM users GROUP BY gender ORDER BY avg_age |
| 标准结果 | Correct SQL query result on the Alibaba Cloud MaxCompute engine (some questions have multiple answers) | {"性别":["Female","Male"],"平均年龄":["27.73","27.84"]} |
| 是否排序 | Whether the question involves sorting | {"性别":["Female","Male"],"平均年龄":[27.73,27.84]} |
| prompt | Model conversation prompt | 已知以下数据集,包含了字段名及其采样信息:... |
How To Use
Environment Setup
-
Step1: Upgrade to V0.7.4 and upgrade the metadata database
For SQLite, the table schema is upgraded automatically by default. For MySQL, you need to run the DDL manually. The file assets/schema/dbgpt.sql contains the complete DDL for the current version. Version-specific DDL changes can be found under assets/schema/upgrade. For example, if you are upgrading from v0.7.1 to v0.7.4, you can run the following DDL:
mysql -h127.0.0.1 -uroot -p{your_password} < assets/schema/upgrade/v0_7_4/upgrade_to_v0.7.4.sql -
Step2: Start the DB-GPT service, and wait for the benchmark dataset to load automatically. When you see the log line, the dataset has finished loading (about 1~5 minute).

- Step3: Register LLM on the DB-GPT platform
- Method 1: Configure via configuration file. Reference: ProxyModel Configuration
- Method 2: Configure via product page. Reference: Models
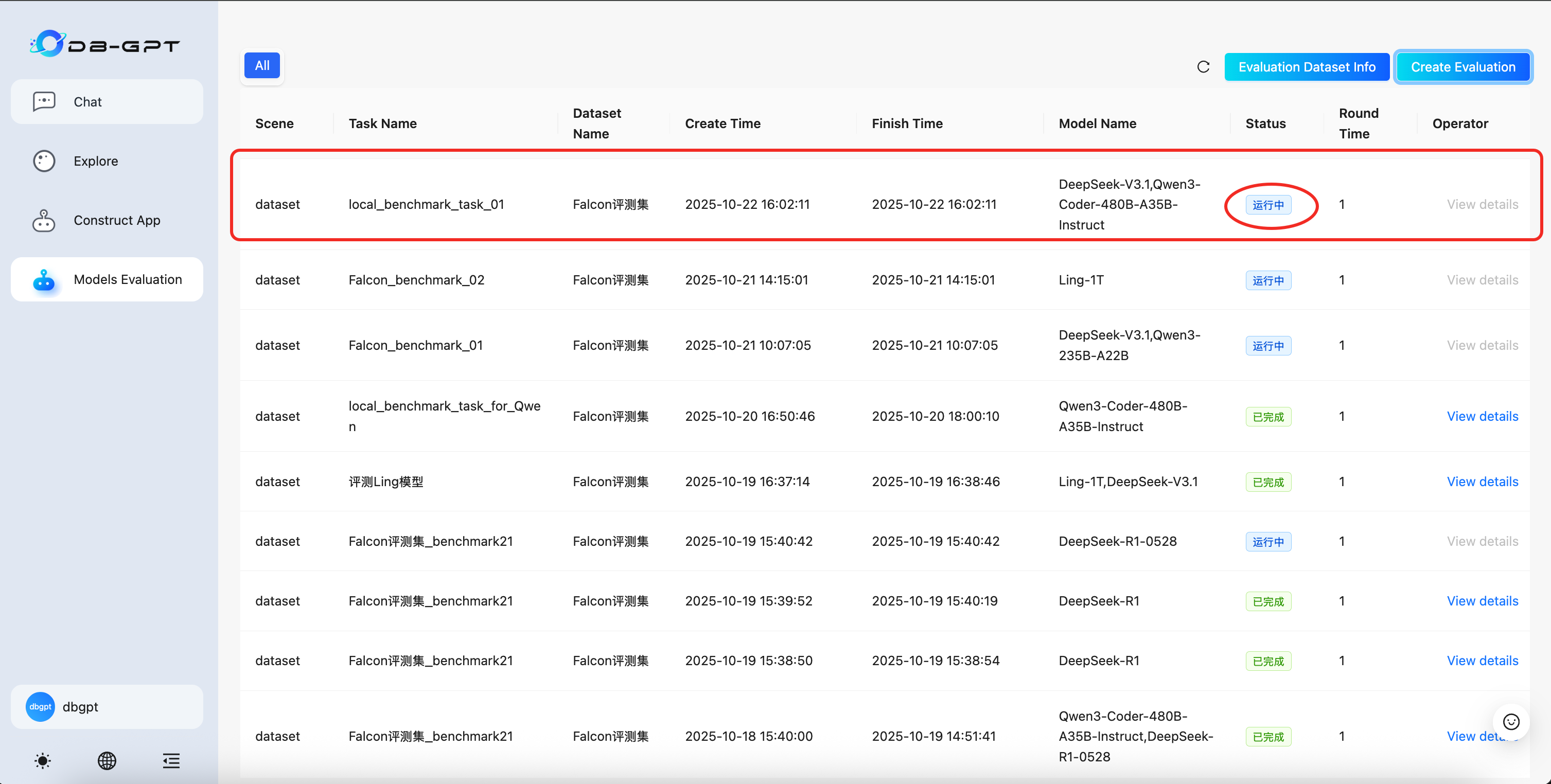
Create Evaluation Task
- Step1: Click "Create Benchmark" to create an evaluation task
- Step2: Enter the task name and select model list
- Step3: Submit the task

- Step4: Wait for the task to complete (evaluation may take a long time)
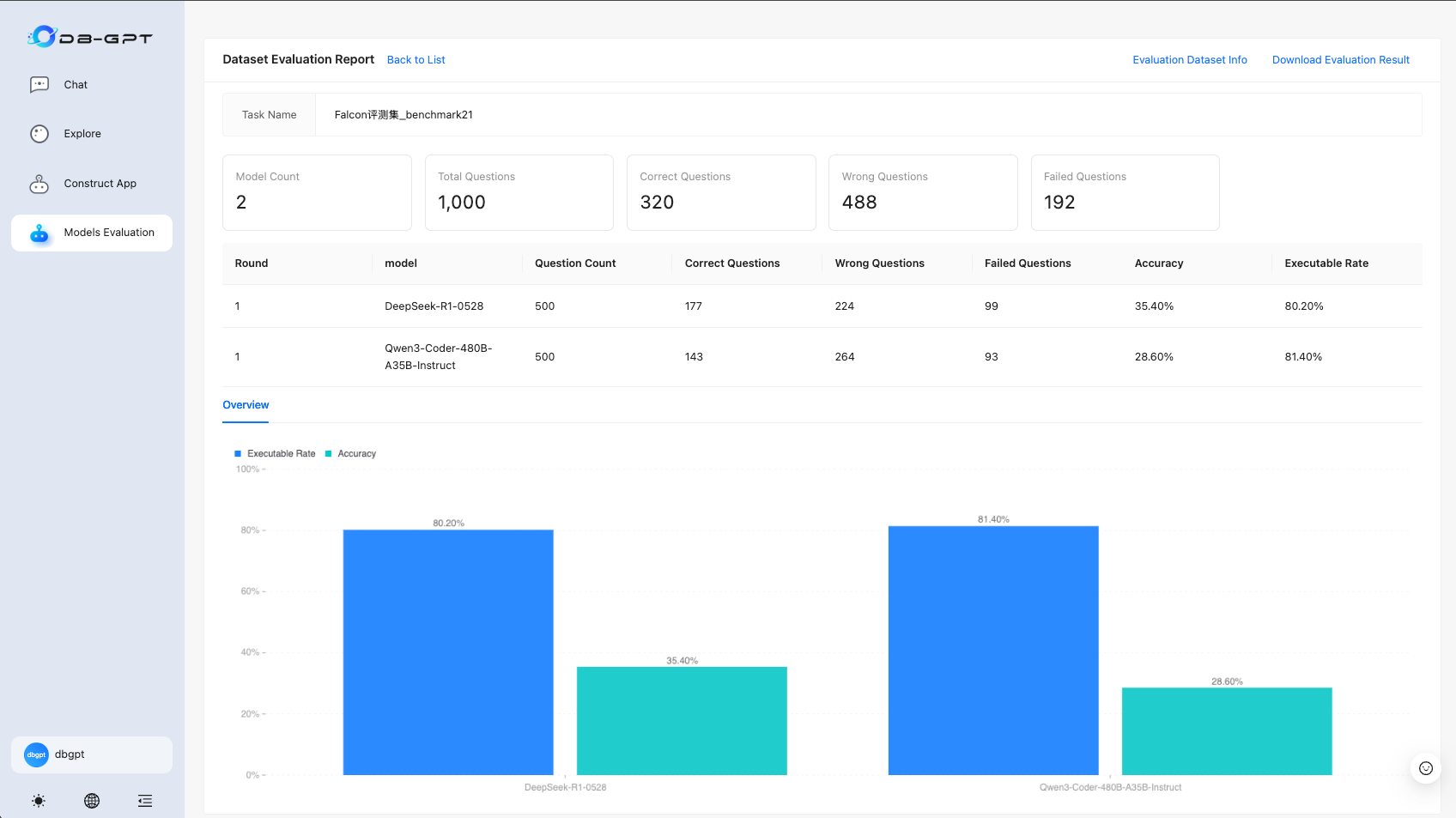
View Evaluation Results
- When the status is "Completed", click "View Details" to see the evaluation report
- The report shows:
- Total number of models, number of questions, numbers of correct, incorrect, and failed questions
- For each round and model: numbers of executed, correct, incorrect, and failed questions; executability rate; accuracy rate
- Bar charts for executability rate and accuracy rate
Correct: the model answered the question correctly. Incorrect: the SQL generated by the model is syntactically correct but semantically wrong. Failed: usually the SQL is syntactically or semantically wrong.
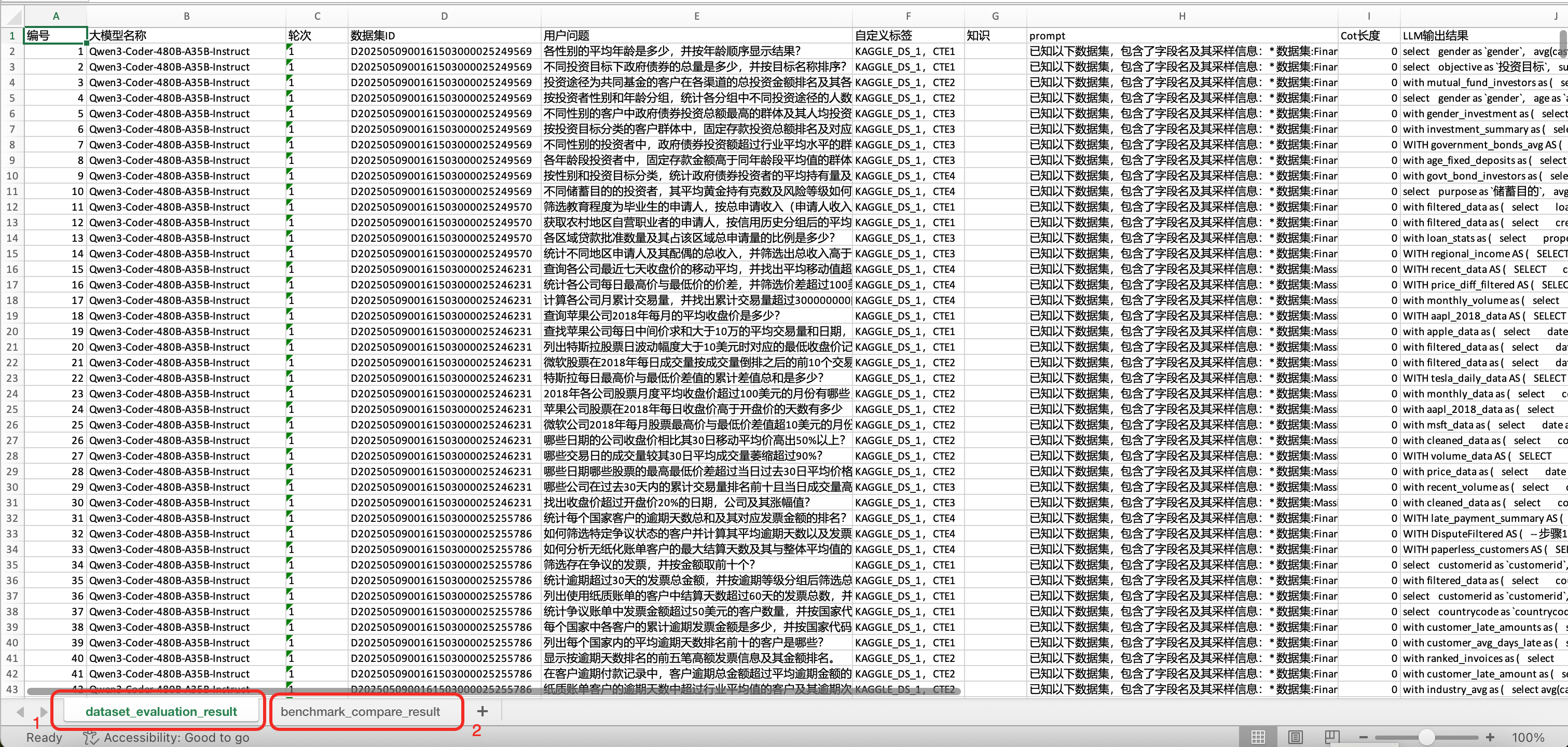
Download Evaluation Results
- Click "Download Evaluation Results" to download the detailed Excel report
- The Excel report includes LLM execution details and comparison results (shown in different sheets)
Dataset Details
- Click "View Dataset Details" to view benchmark details
- Shows tables, fields, and sample data of the Falcon dataset
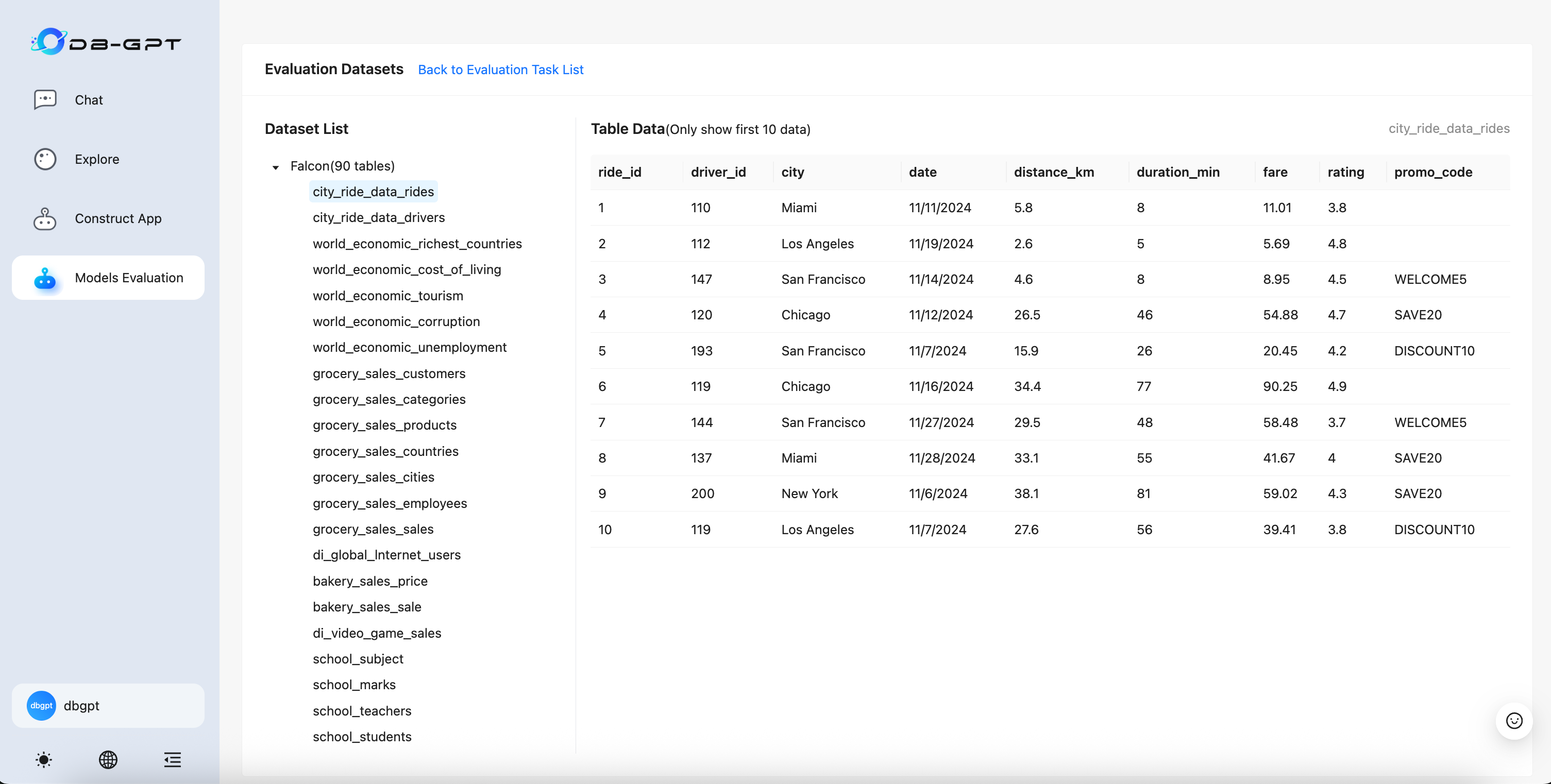
Excel Evaluation Result Data Structure
Excel Evaluation Result Example
Execution Result Example
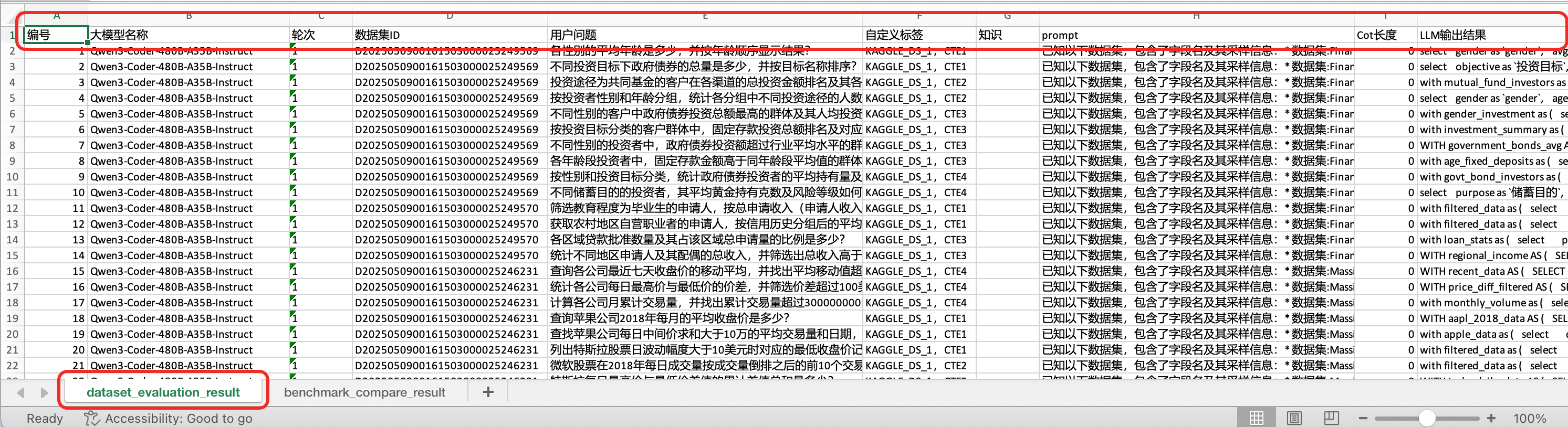
Execution Result Data Structure
- Sheet name: dataset_evaluation_result
| Field | Description | example |
|---|---|---|
| 编号 | Question serial number | 1, 2... |
| 大模型名称 | Name of the evaluated model | DeepSeek-V3.1 |
| 轮次 | Evaluation round | 1 |
| 数据集ID | Dataset ID for the question | D2025050900161503000025249569 |
| 用户问题 | Evaluation question | 各性别的平均年龄是多少,并按年龄顺序显示结果? |
| 自定义标签 | Question source, SQL type | KAGGLE_DS_1, CTE1 |
| 知识 | Knowledge context required | 暂无 |
| prompt | Model conversation prompt | 已知以下数据集,包含了字段名及其采样信息:... |
| Cot长度 | CoT tokens consumed | 100 |
| LLM输出结果 | SQL generated by the LLM | select gender as gender, avg(cast(age as real)) as average_age from di_finance_data group by gender order by avg(cast(age as real)) |
| 结果执行 | Query result of the LLM-generated SQL | {"性别":["Female","Male"],"平均年龄":[27.73,27.84]} |
| 执行结果的报错信息 | Error message if the SQL fails | |
| traceId | Log ID | 暂无 |
| 耗时(秒) | Time consumed | 10 |
Comparison Result Example
Comparison Result Example
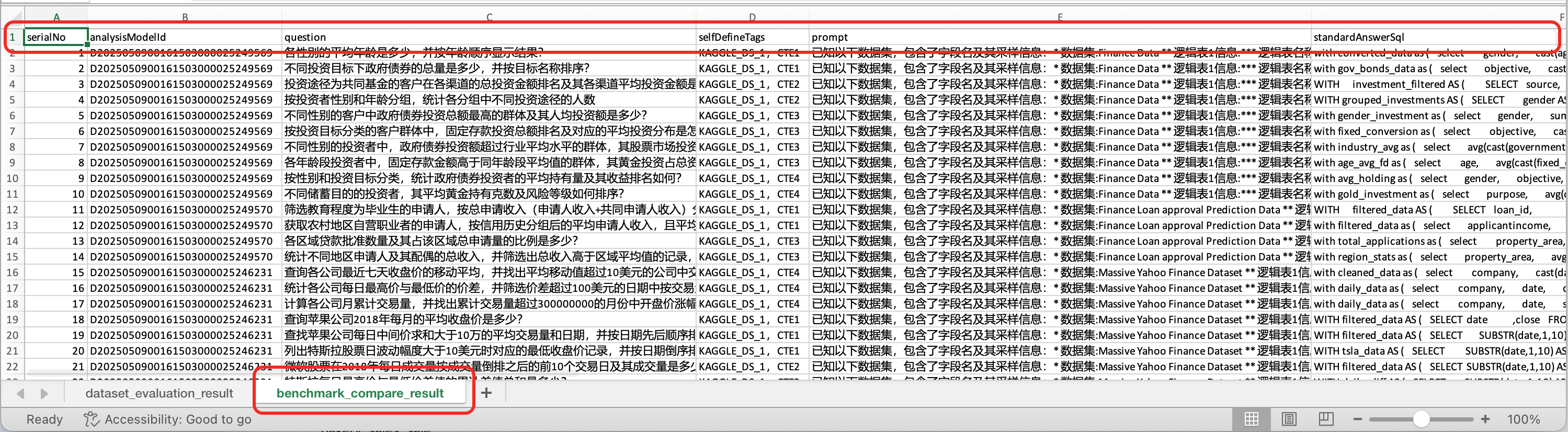
Comparison Result Data Structure
- Sheet name: benchmark_compare_result
| Field | Description | example |
|---|---|---|
| serialNo | Question serial number | 1, 2... |
| analysisModelId | Dataset ID for the question | D2025050900161503000025249569 |
| question | Evaluation question | 各性别的平均年龄是多少,并按年龄顺序显示结果? |
| selfDefineTags | Question source, SQL type | KAGGLE_DS_1, CTE1 |
| prompt | Model conversation prompt | 已知以下数据集,包含了字段名及其采样信息:... |
| standardAnswerSql | Correct SQL for the question(based on Alibaba Cloud MaxCompute syntax) | select gender as gender, avg(cast(age as real)) as average_age from di_finance_data group by gender order by avg(cast(age as real)) |
| standardAnswer | Correct SQL query result on the Alibaba Cloud MaxCompute engine (some questions have multiple answers) | {"性别": ["Female", "Male"], "平均年龄": ["27.73", "27.84"]} |
| llmCode | Evaluated model name | DeepSeek-V3.1 |
| llmOutput | SQL generated by the LLM | select gender as gender, avg(cast(age as real)) as average_age from di_finance_data group by gender order by avg(cast(age as real)) |
| executeResult | Query result of the LLM-generated SQL | {"性别":["Female","Male"],"平均年龄":[27.73,27.84]} |
| errorMsg | Comparison error message | |
| compareResult | Comparison result between the reference answer and the LLM output | RIGHT: correct; WRONG: incorrect; FAILED: failed (usually the SQL has issues) |
Currently Supported Evaluation Capabilities
Metrics
| Metric | Supported |
|---|---|
| Executability Rate | ✅ |
| Accuracy Rate | ✅ |
Datasets
| Dataset | Supported |
|---|---|
| Falcon | ✅ |
Input/Output Formats
| Format | Supported |
|---|---|
| Excel | ✅ |
| CSV | ❌ |
| JSON | ❌ |
| Yuque | ❌ |
Databases
| Database Type | Supported |
|---|---|
| SQLite | ✅ |
| MySQL | ❌ |
| ODPS | ❌ |
Features
- Support single-round multi-model evaluation
- Support Excel File
- Support SQLite Database
- Support multi-round evaluation
- Support evaluating agents
- Support different data sources
- Support CSV, JSON, Yuque, and other file systems