MS-RAG
多源增强检索增强生成框架(MS-RAG)
简介
大语言模型(LLM)能力强大,但它只能基于训练数据进行回答。当用户需要最新的或特定领域的信息—��—例如内部文档、私有数据库或最新报告时——仅靠 LLM 远远不够。
检索增强生成(RAG) 通过从外部知识源中检索相关信息,并将其作为上下文提供给 LLM,从而确保回答基于真实数据而非记忆中的模式。
DB-GPT 实现了 多源 RAG(MS-RAG) 框架,超越了基本的文档问答。它支持多种知识来源(文档、URL、数据库、知识图谱)、多种检索策略(向量、关键词、图谱、混合),并与 DB-GPT 的智能体和工作流生态深度集成。
架构设计
整体流水线
MS-RAG 流水线由四个阶段组成:
知识源 → 分块 → 索引 → 检索 → LLM 生成
- 知识加载 —
KnowledgeFactory根据数据源类型和文件扩展名,自动路由到对应的Knowledge实现类。 - 文档分块 —
ChunkManager使用可配置的策略(按大小、页面、段落、分隔符或 Markdown 标题)将文档切分为可管理的片段。 - 索引构建 —
Assembler类(Embedding、BM25、Summary、DBSchema)将分块持久化到相应的索引存储(向量数据库、全文引擎或知识图谱)。 - 检索与生成 — 查询时,
Retriever检索相关分块,可选的QueryRewrite扩展查询,Ranker对结果重排序,最后由 LLM 生成最终回答。
Assembler 流水线
BaseAssembler 定义了连接所有阶段的统一流水线:
Knowledge.load() → ChunkManager.split() → Assembler.persist() → Assembler.as_retriever()
DB-GPT 提供了四种专用的 Assembler:
| Assembler | 用途 | 索引后端 |
|---|---|---|
| EmbeddingAssembler | 向量相似度 RAG(最常用) | 向量数据库(Chroma、Milvus 等) |
| BM25Assembler | 基于关键词的全文检索 | Elasticsearch |
| SummaryAssembler | 基于摘要的长文档 RAG | 向量数据库 |
| DBSchemaAssembler | 数据库 Schema 检索,用于 Text2SQL 场景 | 向量数据库 |
知识来源
DB-GPT 支持从多种数据源加载知识。在 Web UI 中,上传时可以选择数据源类型:
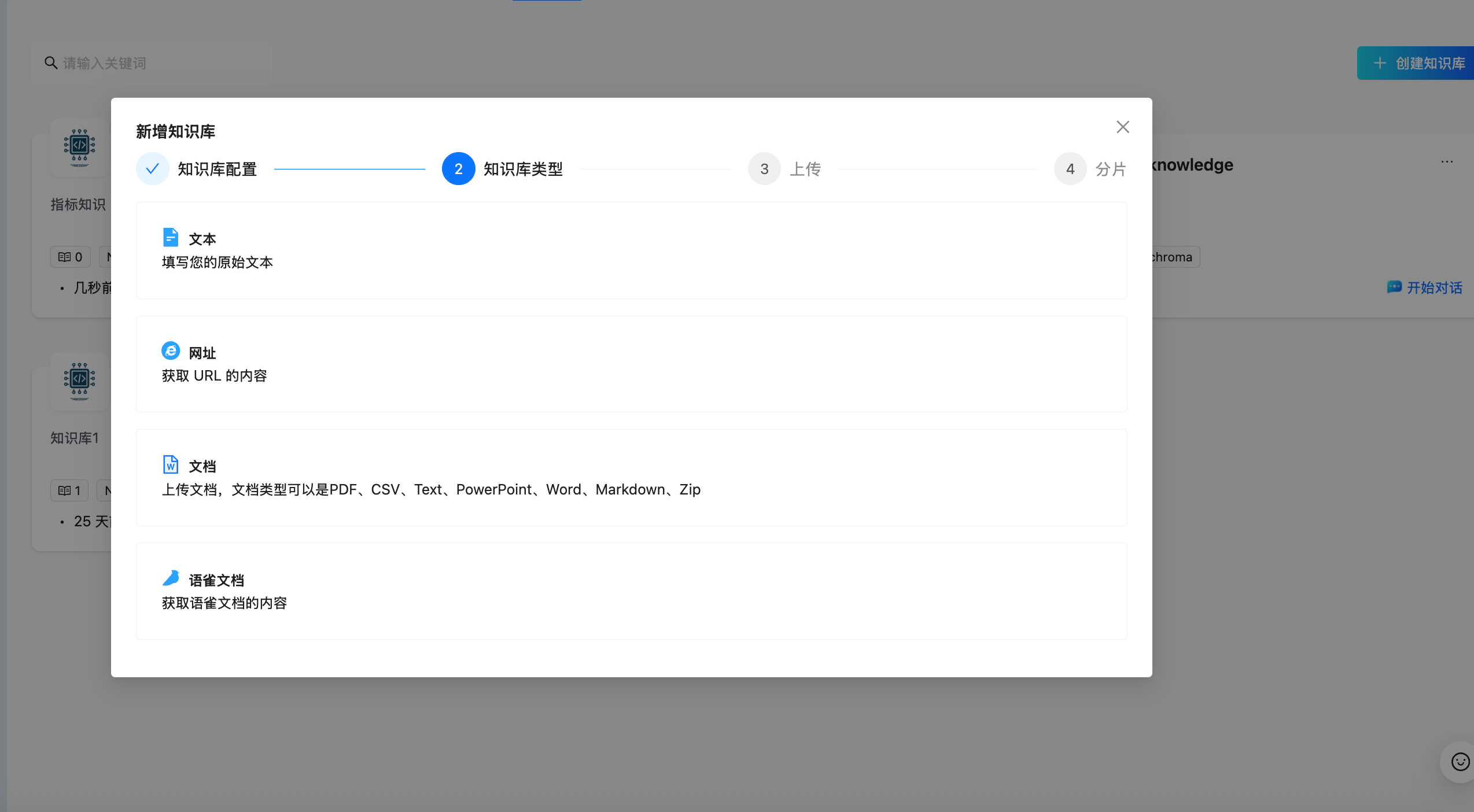
数据源类型
| 类型 | 描述 | 示例 |
|---|---|---|
| 文档 | 上传多种格式的文件 | PDF、Word、Excel、CSV、Markdown、PowerPoint、TXT、HTML、JSON、ZIP |
| 网址 | 抓取并索引网页内容 | 任何可访问的 HTTP/HTTPS URL |
| 文本 | 直接输入原始文本 | 在 UI 中粘贴文本内容 |
| 语雀文档 | 从语雀文档平台导入 | 语雀文档链接 |
支持的文档格式
| 格式 | 扩展名 | 实现类 |
|---|---|---|
.pdf | PDFKnowledge | |
| CSV | .csv | CSVKnowledge |
| Markdown | .md | MarkdownKnowledge |
| Word (docx) | .docx | DocxKnowledge |
| Word (旧版) | .doc | Word97DocKnowledge |
| Excel | .xlsx | ExcelKnowledge |
| PowerPoint | .pptx | PPTXKnowledge |
| 纯文本 | .txt | TXTKnowledge |
| HTML | .html | HTMLKnowledge |
| JSON | .json | JSONKnowledge |
存储类型
创建知识库时,可以从三种存储类型中选择:
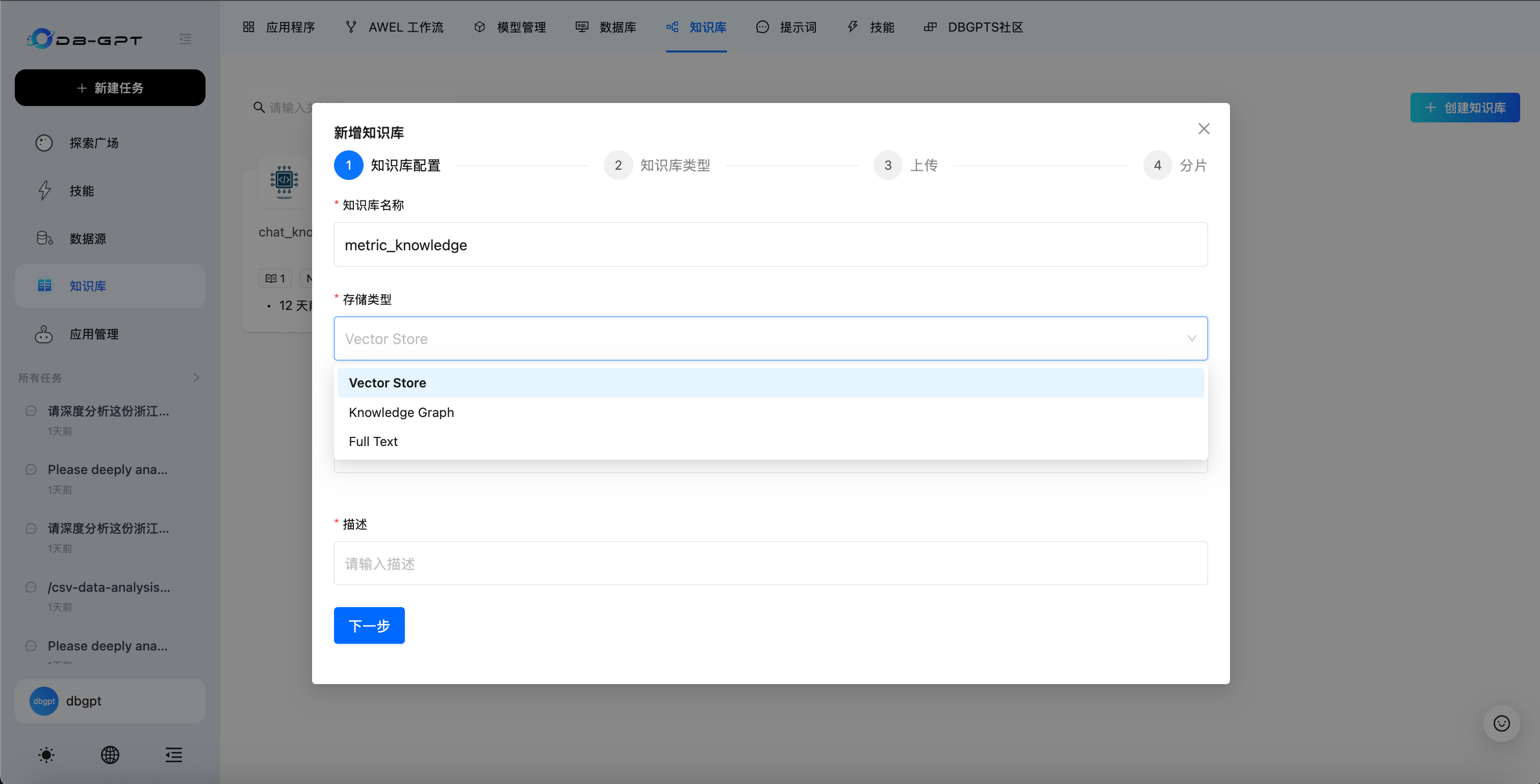
| 存储类型 | 描述 | 适用场景 |
|---|---|---|
| Vector Store(向量存储) | 存储文档嵌入向量,用于语义相似度搜索 | 通用文档问答 |
| Knowledge Graph(知识图谱) | 以图结构存储实体和关系 | 具有复杂实体关系的领域知识 |
| Full Text(全文索引) | 全文索引,用于关键词检索 | 精确术语匹配和关键词搜索 |
向量存储后端
| 后端 | 描述 | 安装依赖 |
|---|---|---|
| ChromaDB | 默认内嵌向量数据库,零配置 | storage_chromadb |
| Milvus | 生产级分布式向量数据库 | storage_milvus |
| PGVector | PostgreSQL 向量扩展 | storage_pgvector |
| Weaviate | 云原生向量搜索引擎 | storage_weaviate |
| Elasticsearch | 全文 + 向量混合搜索 | storage_elasticsearch |
| OceanBase | 云原生分布式数据库 | storage_oceanbase |
知识图谱后端
| 后端 | 描述 |
|---|---|
| TuGraph | 蚂蚁集团高性能图数据库 |
| Neo4j | 流行的开源图数据库 |
| MemGraph | 内存图数据库,低延迟查询 |
全文检索后端
| 后端 | 描述 |
|---|---|
| Elasticsearch | 行业标准全文搜索引擎 |
| OpenSearch | AWS 托管的搜索和分析套件 |
检索策略
DB-GPT 提供多种检索模式。可以在知识库设置中配置检索模式:
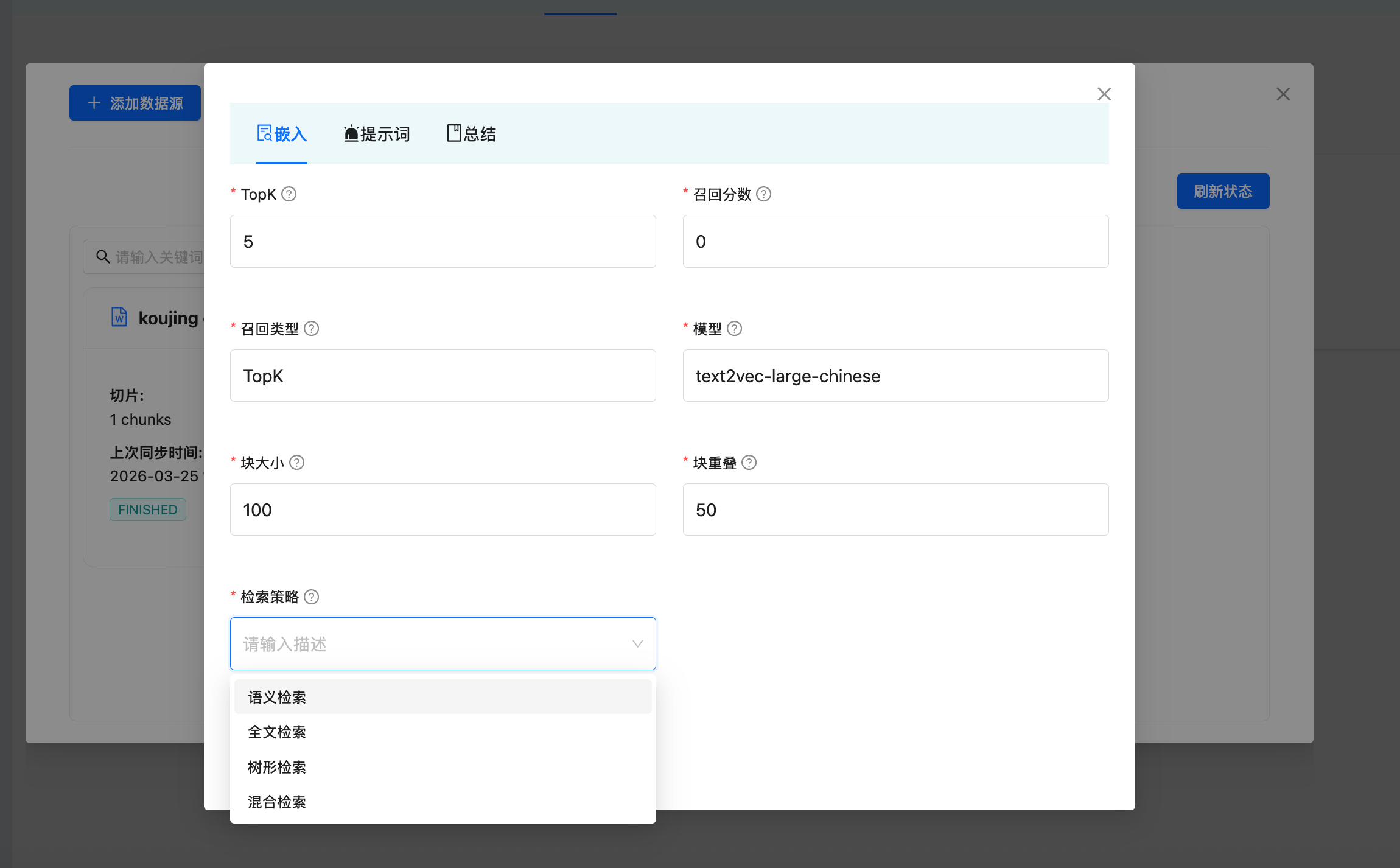
| 策略 | 描述 | 所需后端 |
|---|---|---|
| Semantic(语义检索) | 使用嵌入向量进行语义相似度搜索 | 向量数据库 |
| Keyword(关键词检索) | 基于 BM25 的关键词匹配 | Elasticsearch |
| Hybrid(混合检索) | 结合向量 + 关键词搜索,使用倒数排名融合(RRF) | 向量数据库 + Elasticsearch |
| Tree(树状检索) | 面向层级文档的树状结构检索 | 向量数据库 |
查询增强
除了基础检索,DB-GPT 还提供高级查询处理能力:
- 查询改写(Query Rewrite) — 使用 LLM 将原始查询扩展和改写为多个搜索查询,提升召回率。
- 重排序(Reranking) — 初步检索后,使用 Reranker 模型对结果重新评分和排序,提高精准度。
支持的重排序器
| 重排序器 | 类型 | 描述 |
|---|---|---|
| CrossEncoderRanker | 本地 | 使用 sentence-transformers CrossEncoder 模型 |
| QwenRerankEmbeddings | 本地 | 基于 transformers 的 Qwen3-Reranker |
| OpenAPIRerankEmbeddings | API | 兼容 OpenAI 风格的 Rerank API |
| RRFRanker | 算法 | 倒数排名融合,用于合并多源检索结果 |
| DefaultRanker | 算法 | 基于分数的简单排序 |
分块策略
文档分块是影响 RAG 质量的关键步骤。DB-GPT 支持多种分块策略:
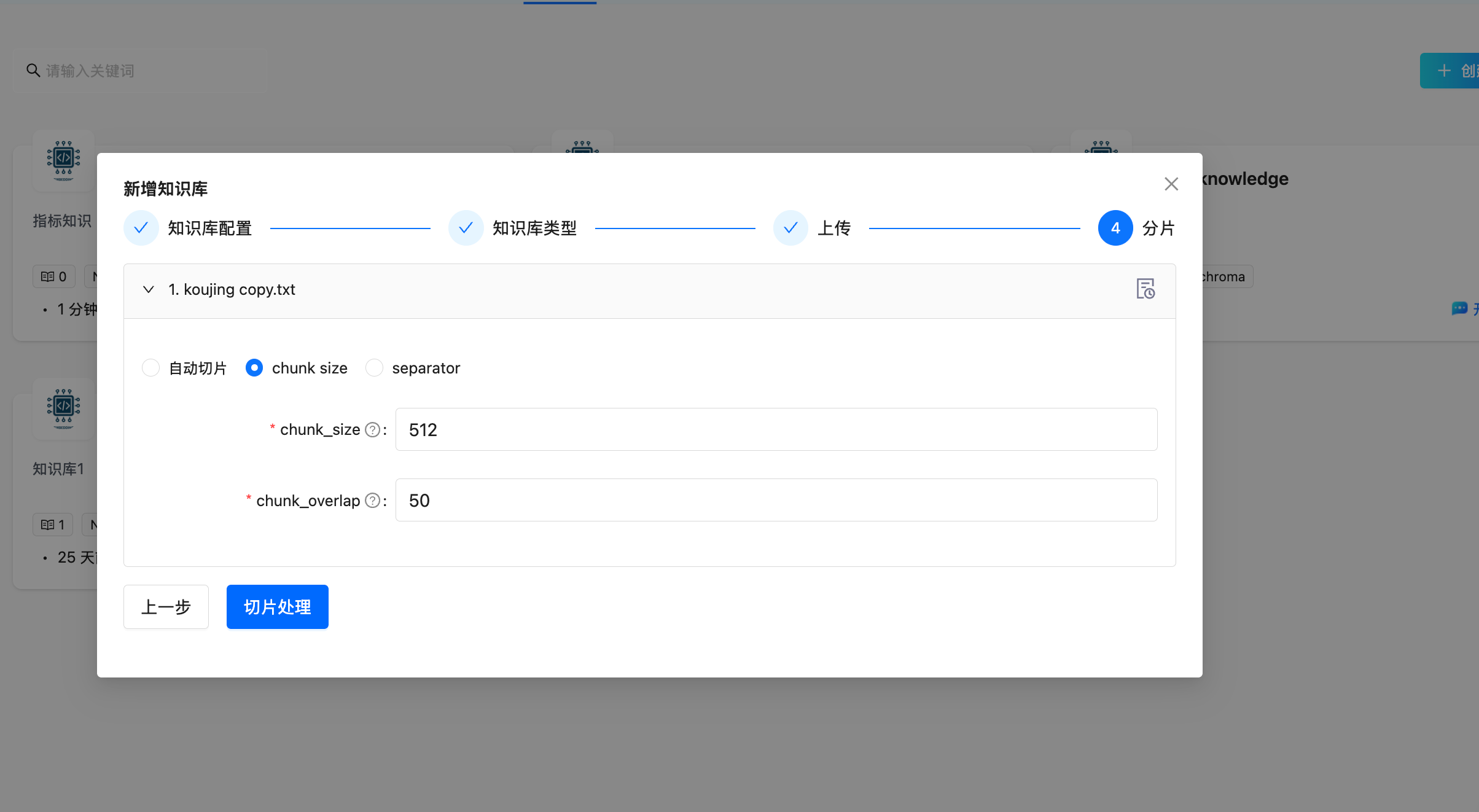
| 策略 | 分割器 | 描述 |
|---|---|---|
| 按大小分块 | RecursiveCharacterTextSplitter | 按字符数切分,可配置大小和重叠(默认:512 / 50) |
| 按页分块 | PageTextSplitter | 在页面边界处切分(适用于 PDF) |
| 按段落分块 | ParagraphTextSplitter | 在段落边界处切分 |
| 按分隔符分块 | SeparatorTextSplitter | 在自定义分隔符处切分 |
| 按 Markdown 标题分块 | MarkdownHeaderTextSplitter | 在 Markdown 标题层级处切分 |
分块参数
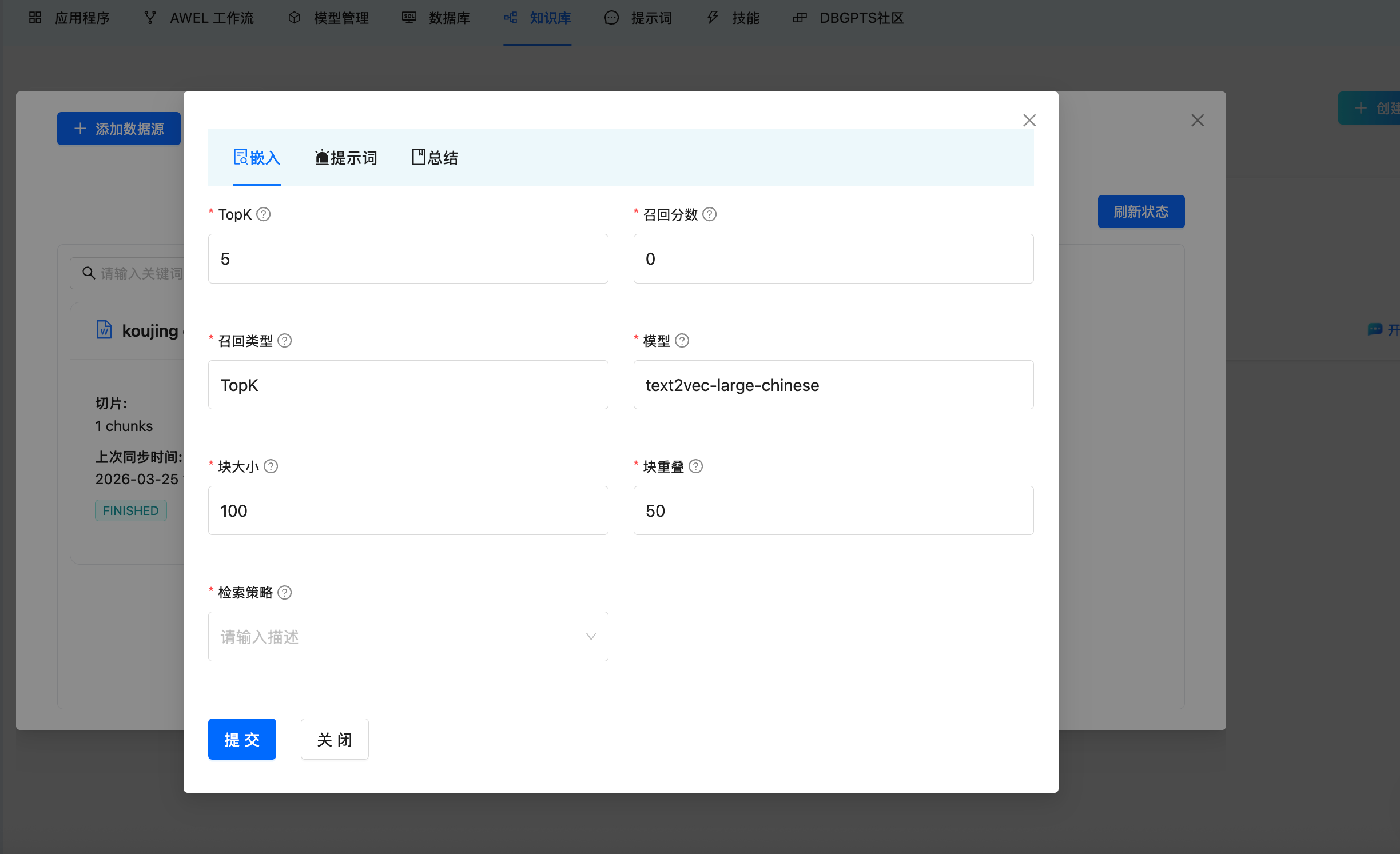
| 参数 | 描述 | 默认值 |
|---|---|---|
| chunk_size | 每个分块的最大字符数 | 512 |
| chunk_overlap | 相邻分块的重叠字符数 | 50 |
| topk | 每次查询检索的分块数量 | 5 |
| recall_score | 最低相关性分数阈值 | 0 |
| recall_type | 召回策略 | TopK |
| model | 使用的嵌入模型 | 取决于配置 |
嵌入模型
DB-GPT 支持多种嵌入模型,将文本转换为向量表示:
本地模型
| 模型 | 实现类 | 描述 |
|---|---|---|
| HuggingFace | HuggingFaceEmbeddings | 通用 HuggingFace 模型 |
| BGE 系列 | HuggingFaceBgeEmbeddings | BAAI BGE 模型,支持指令跟随(中英文) |
| Instructor | HuggingFaceInstructEmbeddings | 指令跟随嵌入模型 |
远程 API 模型
| 提供商 | 实现类 | 描述 |
|---|---|---|
| OpenAI 兼容 | OpenAPIEmbeddings | 任何 OpenAI 兼容的嵌入 API |
| Jina | JinaEmbeddings | Jina AI 嵌入服务 |
| Ollama | OllamaEmbeddings | 本地 Ollama 嵌入服务 |
| 通义(阿里云) | TongyiEmbeddings | 阿里云灵积平台 |
| 千帆(百度) | QianfanEmbeddings | 百度文心平台 |
| SiliconFlow | SiliconFlowEmbeddings | SiliconFlow 嵌入服务 |
知识图谱 RAG
除了传统的向量 RAG,DB-GPT 还支持 知识图谱 RAG,用于结构化知识检索。
工作原理
- 三元组抽取 — LLM 从文档中抽取实体和关系,形成(主体、谓词、客体)三元组。
- 图谱存储 — 三元组存储到图数据库(TuGraph、Neo4j 或 MemGraph)。
- 图谱检索 — 查询时,
GraphRetriever组合四种子策略:- 基于关键词 — 通过抽取的关键词匹配图节点
- 基于向量 — 在图节点嵌入上进行语义相似度搜索
- 基于文本 — 通过 LLM 将自然语言转换为图查询语言(Text2GQL)
- 基于文档 — 通过文档-图谱关联进行检索
- 社区摘要 — 对图谱社区进行摘要,提供高层次的知识理解。
使用方式
通过 Web UI 创建知识库
第 1 步 — 打开知识管理
在侧边栏中点击 知识库 进入知识管理页面。
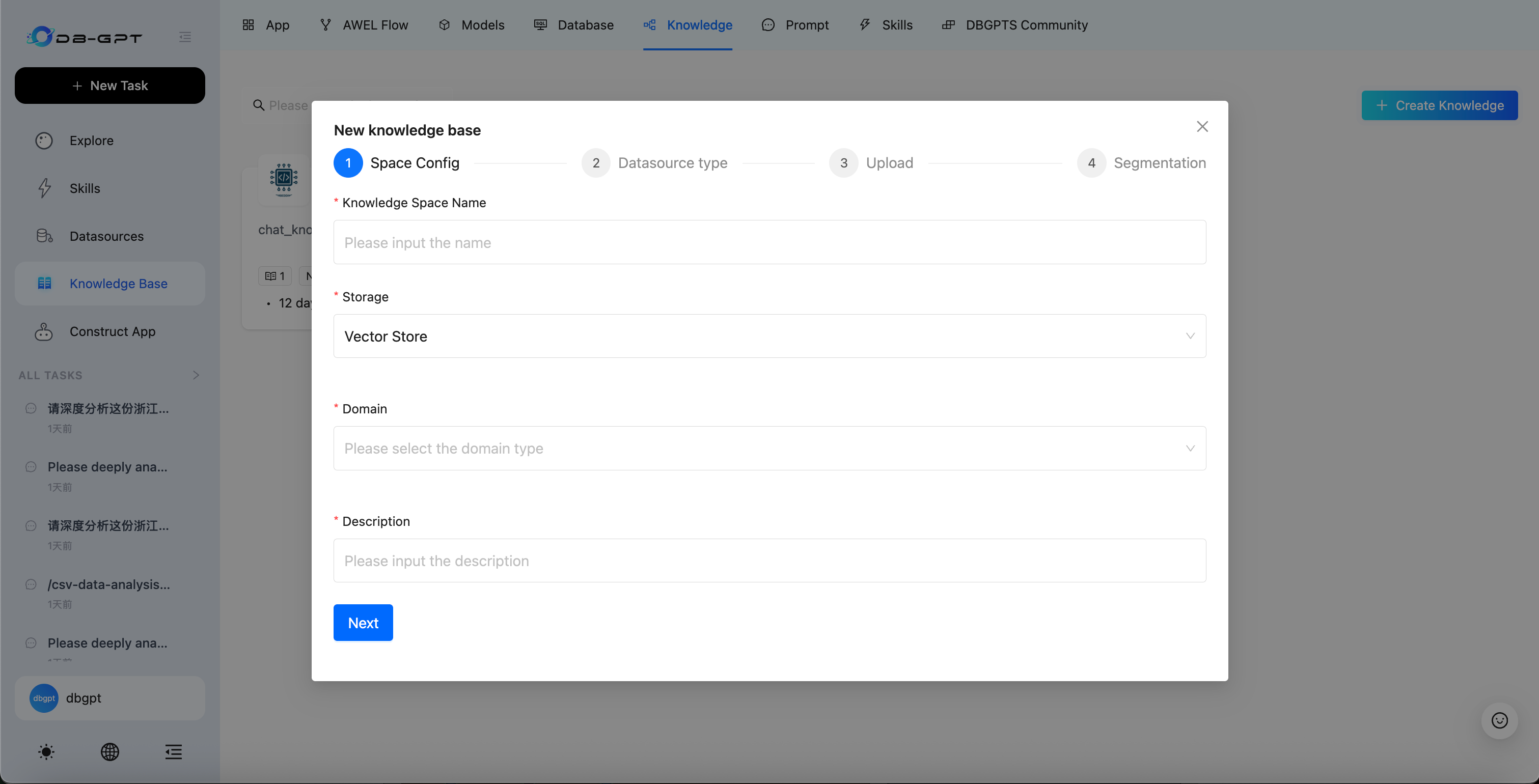
第 2 步 — 创建并配置
- 点击 创建知识库 开始新建。
- 选择 存储类型(向量存储、知识图谱或全文索引)。
- 选择 嵌入模型 并配置分块参数。
第 3 步 — 上传数据
选择数据源类型并上传内容。支持的类型包括文档(PDF、Word、Excel、CSV 等)、网址、文本和语雀文档。
第 4 步 — 配置分块
选择分块策略并设置参数:
第 5 步 — 配置检索策略(可选)
您可以为知识库配置检索策略。DB-GPT 支持多种检索模式 — Semantic(语义检索)、Keyword(关键词检索)、Hybrid(混合检索) 和 Tree(树状检索) — 以适应不同的查询场景。在知识库设置中选择最适合您使用场景的模式。
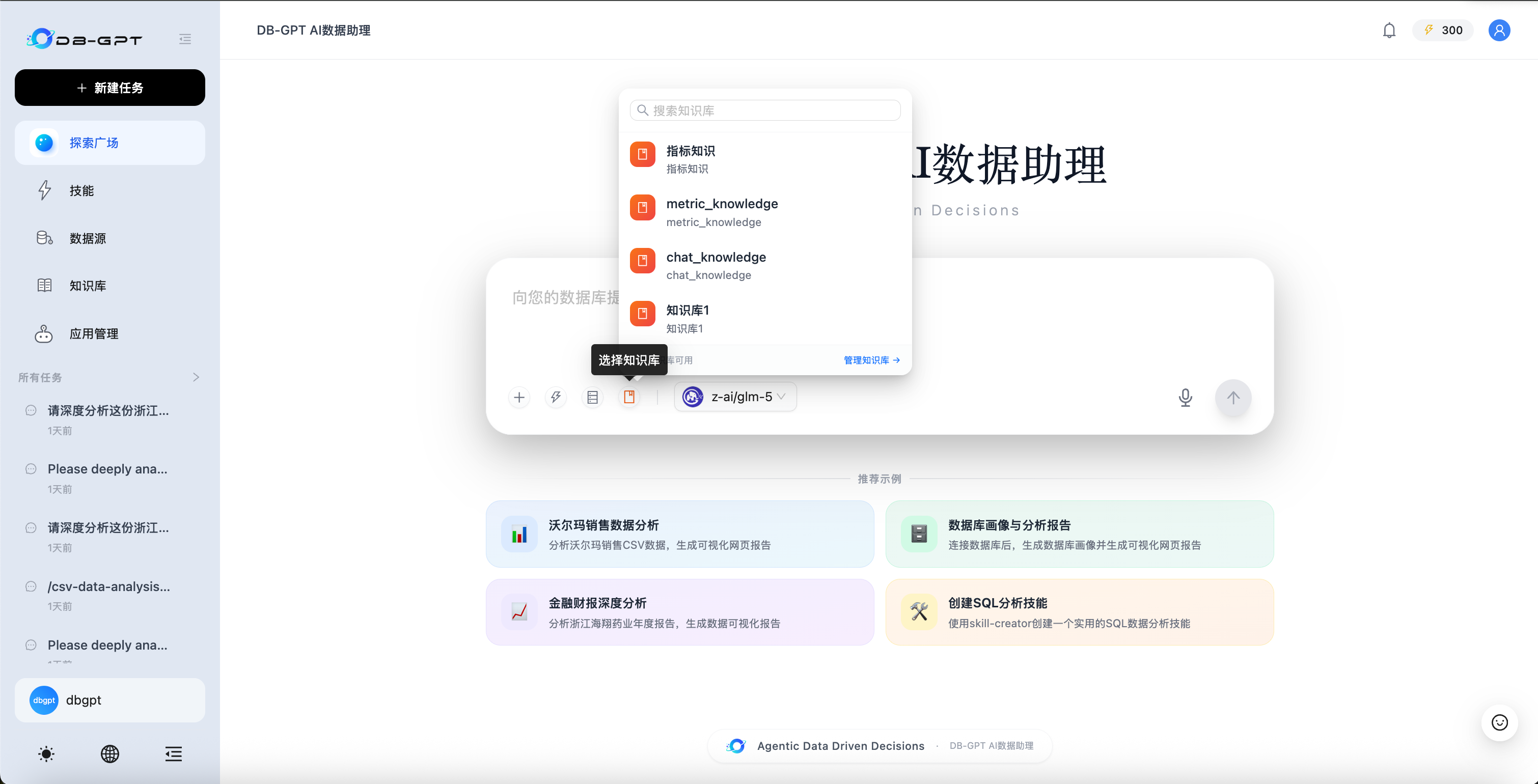
第 6 步 — 与知识库对话
进入 �对话 页面,点击输入框工具栏中的知识库图标,从下拉列表中选择您的知识库,即可开始提问。
编程方式(Python API)
from dbgpt.rag import Chunk
from dbgpt_ext.rag.assembler import EmbeddingAssembler
from dbgpt_ext.rag.knowledge import KnowledgeFactory
# 从文件加载知识
knowledge = KnowledgeFactory.create(file_path="your_document.pdf")
# 构建嵌入索引
assembler = await EmbeddingAssembler.aload_from_knowledge(
knowledge=knowledge,
index_store=your_vector_store,
embedding_model=your_embedding_model,
)
assembler.persist()
# 检索相关分块
retriever = assembler.as_retriever(top_k=5)
chunks = await retriever.aretrieve("主要内容是什么?")
更多资源
| 主题 | 链接 |
|---|---|
| 知识库 Web UI 使用指南 | 知识库 |
| RAG 概念 | RAG |
| 知识图谱 RAG 配置 | Graph RAG |
| AWEL RAG 算子 | AWEL |
| 源代码 | GitHub |