Fine-Tuning use dbgpt_hub
The DB-GPT-Hub project has released a pip package to lower the threshold for Text2SQL training. In addition to fine-tuning through the scripts provided in the warehouse, you can alse use the Python package we provide for fine-tuning.
Install
pip install dbgpt_hub
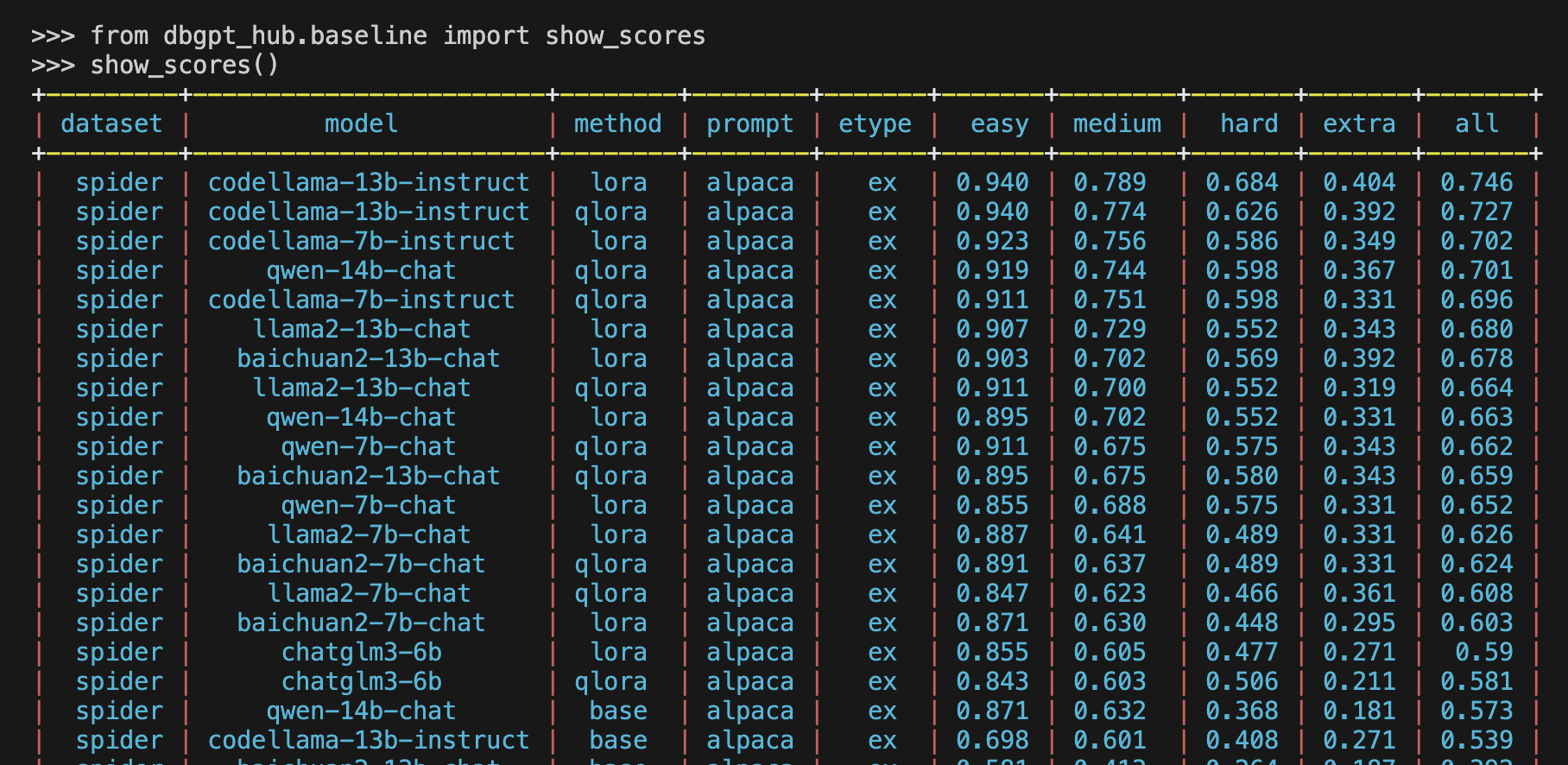
Show Baseline
from dbgpt_hub.baseline import show_scores
show_scores()
Fine-tuning
from dbgpt_hub.data_process import preprocess_sft_data
from dbgpt_hub.train import train_sft
from dbgpt_hub.predict import start_predict
from dbgpt_hub.eval import start_evaluate
Preprocessing data into fine-tuned data format.
data_folder = "dbgpt_hub/data"
data_info = [
{
"data_source": "spider",
"train_file": ["train_spider.json", "train_others.json"],
"dev_file": ["dev.json"],
"tables_file": "tables.json",
"db_id_name": "db_id",
"is_multiple_turn": False,
"train_output": "spider_train.json",
"dev_output": "spider_dev.json",
}
]
preprocess_sft_data(
data_folder = data_folder,
data_info = data_info
)
Fine-tune the basic model and generate model weights
train_args = {
"model_name_or_path": "codellama/CodeLlama-13b-Instruct-hf",
"do_train": True,
"dataset": "example_text2sql_train",
"max_source_length": 2048,
"max_target_length": 512,
"finetuning_type": "lora",
"lora_target": "q_proj,v_proj",
"template": "llama2",
"lora_rank": 64,
"lora_alpha": 32,
"output_dir": "dbgpt_hub/output/adapter/CodeLlama-13b-sql-lora",
"overwrite_cache": True,
"overwrite_output_dir": True,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 16,
"lr_scheduler_type": "cosine_with_restarts",
"logging_steps": 50,
"save_steps": 2000,
"learning_rate": 2e-4,
"num_train_epochs": 8,
"plot_loss": True,
"bf16": True,
}
start_sft(train_args)
Predictive model output results
predict_args = {
"model_name_or_path": "codellama/CodeLlama-13b-Instruct-hf",
"template": "llama2",
"finetuning_type": "lora",
"checkpoint_dir": "dbgpt_hub/output/adapter/CodeLlama-13b-sql-lora",
"predict_file_path": "dbgpt_hub/data/eval_data/dev_sql.json",
"predict_out_dir": "dbgpt_hub/output/",
"predicted_out_filename": "pred_sql.sql",
}
start_predict(predict_args)
Evaluate the accuracy of the output results on the test datasets
evaluate_args = {
"input": "./dbgpt_hub/output/pred/pred_sql_dev_skeleton.sql",
"gold": "./dbgpt_hub/data/eval_data/gold.txt",
"gold_natsql": "./dbgpt_hub/data/eval_data/gold_natsql2sql.txt",
"db": "./dbgpt_hub/data/spider/database",
"table": "./dbgpt_hub/data/eval_data/tables.json",
"table_natsql": "./dbgpt_hub/data/eval_data/tables_for_natsql2sql.json",
"etype": "exec",
"plug_value": True,
"keep_distict": False,
"progress_bar_for_each_datapoint": False,
"natsql": False,
}
start_evaluate(evaluate_args)