SMMF
Service-oriented Multi-model Management Framework(SMMF)
Introduction
In AIGC application exploration and production landing, it is difficult to avoid directly interfacing with modeling services, but at present there is no de facto standard for the deployment of inference of large models, new models are constantly released and new training methods are constantly proposed, and we need to spend a lot of time adapting to the changing underlying modeling environments, which to a certain extent restricts the exploration and landing of AIGC applications
System Design
In order to simplify the model adaptation process and improve model deployment efficiency and performance, we proposed a service-oriented Multi-Model Management Framework (SMMF).
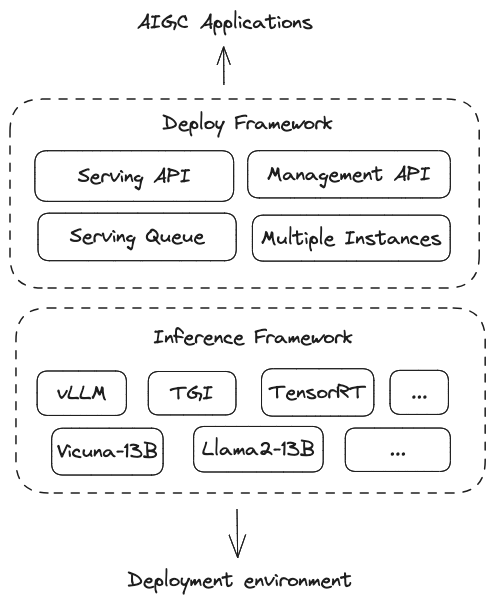
SMMF consists of two parts: model inference layer and model deployment layer. The model inference layer corresponds to the model inference framework vLLM, TGI and TensorRT, etc. The model deployment layer connects downward to the inference layer and provides model service capabilities upward. The model deployment framework is based on the inference framework and provides capabilities such as multiple model instances, multiple inference frameworks, multi-cloud, automatic expansion and contraction[1] , and observability[2]
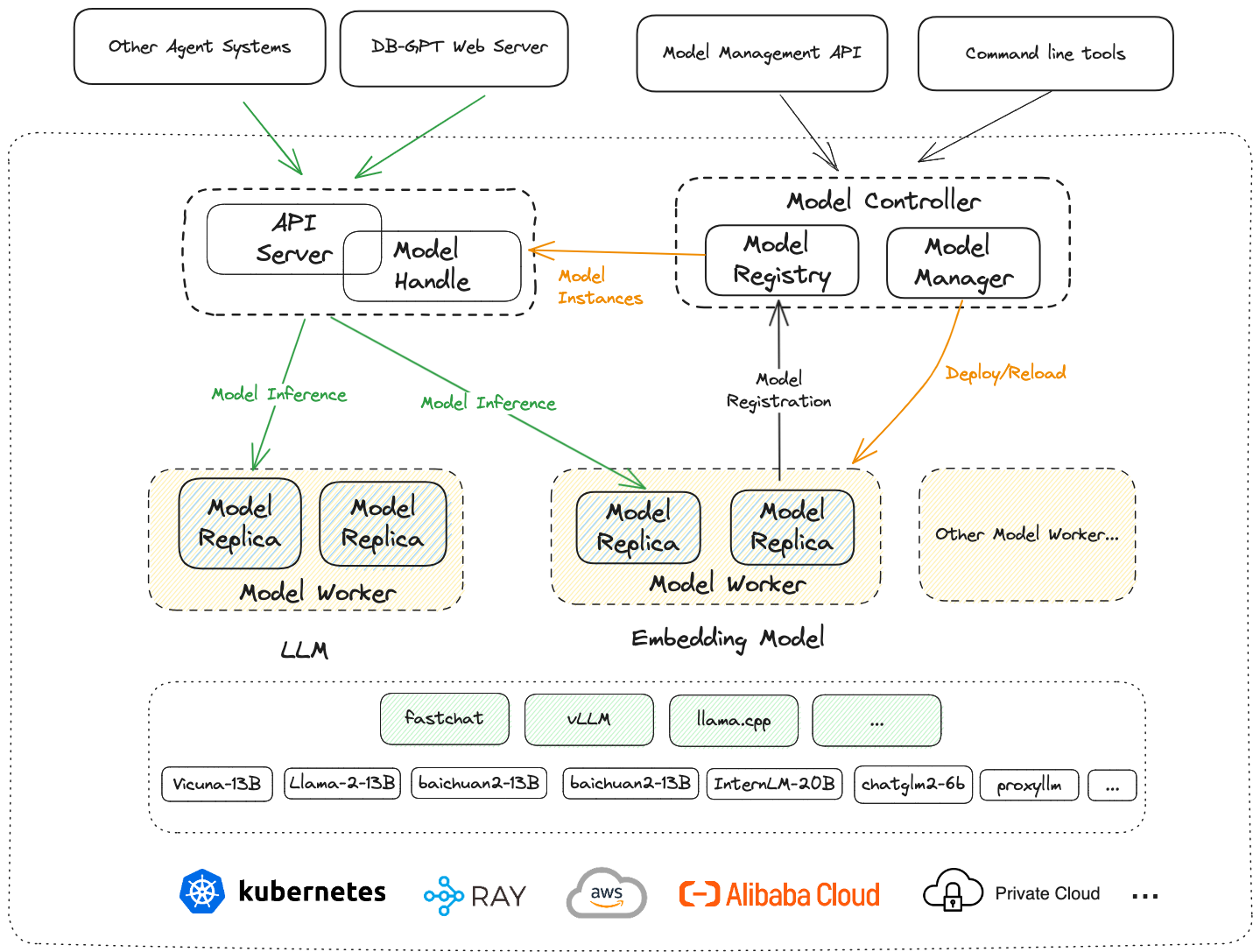
In DB-GPT, SMMF is specifically shown in the figure above: the top layer corresponds to the service and application layer (such as DB-GPT WebServer, Agents system, applications, etc.). The next layer is the model deployment framework layer, which includes the API Server and Model Handle that provide model services to the application layer, the Metadata Management and Control Center Model Controller of the entire deployment framework, and the Model Worker that directly interfaces with the inference framework and the underlying environment. The next layer is the inference framework layer, which includes vLLM, llama.cpp and FastChat (since DB-GPT directly uses the inference interface of FastChat, here we also classify FastChat as an inference framework), large language models (Vicuna, Llama, Baichuan, ChatGLM), etc. are deployed in the inference framework. The bottom layer is the actual deployment environment, including Kubernetes, Ray, AWS, Alibaba Cloud, private cloud, etc
SMMF features
-
Supports multiple models and multiple inference frameworks
-
Scalability and stability
-
High framework performance
-
Manageable and monitorable
-
Lightweight
Multiple models and multiple inference frameworks
The current development in the field of large models is changing with each passing day. New models are constantly being released, and new methods are constantly being proposed in terms of model training and inference. We judge that this situation will continue for some time.
For most users exploring and implementing AIGC application scenarios, this situation has both advantages and disadvantages. A typical drawback is to be "led by the nose" by the model, and it is necessary to constantly try and explore new models and new reasoning frameworks.
In DB-GPT, seamless support for FastChat, vLLM and llama.cpp is directly provided. In theory, DB-GPT supports all the models they support. If you have needs for reasoning speed and tactical capabilities, you can directly use vLLM , if you want the CPU or Mac's M1/M2 chip to also get good inference performance, you can use llama.cpp. In addition, DB-GPT also supports proxy models, such as: OpenAI, Azure, Google Bard, Tongyi, Baichuan, Xun Feixinghuo, Baidu Wenxin, Zhipu AI, etc
Support LLMs
Open-source Models
- Vicuna
- vicuna-13b-v1.5
- LLama2
- baichuan2-13b
- baichuan2-7b
- chatglm-6b
- chatglm2-6b
- chatglm3-6b
- falcon-40b
- internlm-chat-7b
- internlm-chat-20b
- qwen-7b-chat
- qwen-14b-chat
- wizardlm-13b
- orca-2-7b
- orca-2-13b
- openchat_3.5
- zephyr-7b-alpha
- mistral-7b-instruct-v0.1
- Yi-34B-Chat
Proxy Models
More LLMs, please refer to the source code
Scalability and stability
The cloud native field solves the core pain points of management, control, scheduling, and utilization of massive computing resources. Let the value of computing be fully released, making large-scale computing a ubiquitous technology.
In the field of large models, we are also concerned about the explosive demand for computing resources during model inference. Therefore, multi-model management with scheduling supercomputing capabilities is what we focus on during production implementation. In view of the outstanding achievements of computing scheduling layers such as Kubernetes and Istio in the past few years, we fully draw on relevant design concepts in multi-model management and control.
A relatively complete model deployment framework requires multiple parts, including a Model Worker that directly interfaces with the underlying reasoning framework, a Model Controller that manages and maintains multiple model components, and a Model API that provides external model service capabilities. The Model Worker must be scalable. It can be a Model Worker that specifically deploys large language models, or a Model Worker that is used to deploy Embedding models. Of course, it can also be based on the deployment environment, such as physical machine environment, kubernetes environment, and some specific clouds. Choose different Model Workers based on the cloud environment provided by the service provider.
The Model Controller used to manage metadata also needs to be extensible, and different Model Controllers must be selected for different deployment environments and different model management and control requirements. In addition, from a technical point of view, model services have a lot in common with traditional microservices. In microservices, a certain service in the microservice can have multiple service instances, and all service instances are uniformly registered to the registration center. The service caller pulls the service list corresponding to the service name from the registration center based on the service name, and then selects a specific service instance to call according to a certain load balancing policy.
In model deployment, a similar architecture can also be considered. A certain model can have multiple model instances. All model instances are uniformly registered to the model registration center, and then the model service caller goes to the registration center to pull the model instance based on the model name. list, and then call a specific model instance according to the load balancing policy of the model.
Here we introduce the model registration center, which is responsible for storing model instance metadata in the Model Controller. It can directly use the registration center in existing microservices as an implementation (such as nacos, eureka, etcd and console, etc.), so that the entire deployment system is Can achieve high availability.
High framework performance
The framework layer should not be the bottleneck of model inference performance. In most cases, the hardware and inference framework determines the capability of the model service, and the deployment and optimization of model inference is a complex project, and inappropriate framework design may increase this complexity. In our opinion, there are two main concerns in deploying the framework in order to "not drag the feet" on performance: ● The framework should not be the bottleneck of model inference performance.
Avoid excessive encapsulation: the more encapsulation and the longer the links, the harder it is to troubleshoot performance issues.
High-performance communication design: There are many points in high-performance communication design, so I won't go into them here. Since Python is currently taking the lead in AIGC applications, in Python, asynchronous interfaces are critical to the performance of the service. Therefore, the model service layer only provides asynchronous interfaces to make compatibility with the model reasoning framework docking layer, and directly dock if the model reasoning framework provides asynchronous interfaces. Otherwise use synchronous to asynchronous task support.
Manageable and monitorable
In AIGC application exploration or AIGC application production and implementation, we need the model deployment system to have certain management capabilities, and to perform certain management and control on model instances deployed through API or command line (such as: online, offline, restart, debug, etc.)
Observability is a very important capability of production systems. We believe that observability is crucial in AIGC applications. Because the user experience and the interaction between the user and the system are more complex, in addition to traditional observation indicators, we are also more concerned about the user's input information and the contextual information of the corresponding scene. Which model instance and model parameters were called, the output content and response time of the model, user feedback, etc.
We can find some performance bottlenecks of model services and some user experience data from this information.
What about response latency?
Does it solve user problems and extract user satisfaction, etc. from user content?
These are the basis for further optimization of the entire application.
Lightweight
Considering the numerous supported models and inference frameworks, we need to work hard to avoid unnecessary dependencies and ensure that users can install them as needed.
In DB-GPT, users can install their own dependencies on demand. Some of the main optional dependencies are as follows:
-
Install the most basic dependencies
pip install -e .orpip install -e ".[core]" -
Install the dependencies of the basic framework
pip install -e ".[framework]" -
Install the dependencies of the openai proxy model
pip install -e ".[openai]" -
Install default dependencies
pip install -e ".[default]" -
Install dependencies of vLLM inference framework
pip install -e ".[vllm]" -
Install dependencies for model quantization deployment
pip install -e ".[quantization]" -
Install knowledge base related dependencies
pip install -e ".[knowledge]" -
Install pytorch dependencies
pip install -e ".[torch]" -
Install the dependencies of llama.cpp
pip install -e ".[llama_cpp]" -
Install vectorized database dependencies
pip install -e ".[vstore]" -
Install data source dependencies
pip install -e ".[datasource]"
Implementation
For multi-model related implementation, please refer to the source code
Appendix
[1] [2] Capabilities such as automatic scaling and observability are still in incubation and have not yet been implemented.