High Availability
Architecture
Here is the architecture of the high availability cluster, more details can be found in the cluster deployment mode and SMMF module.
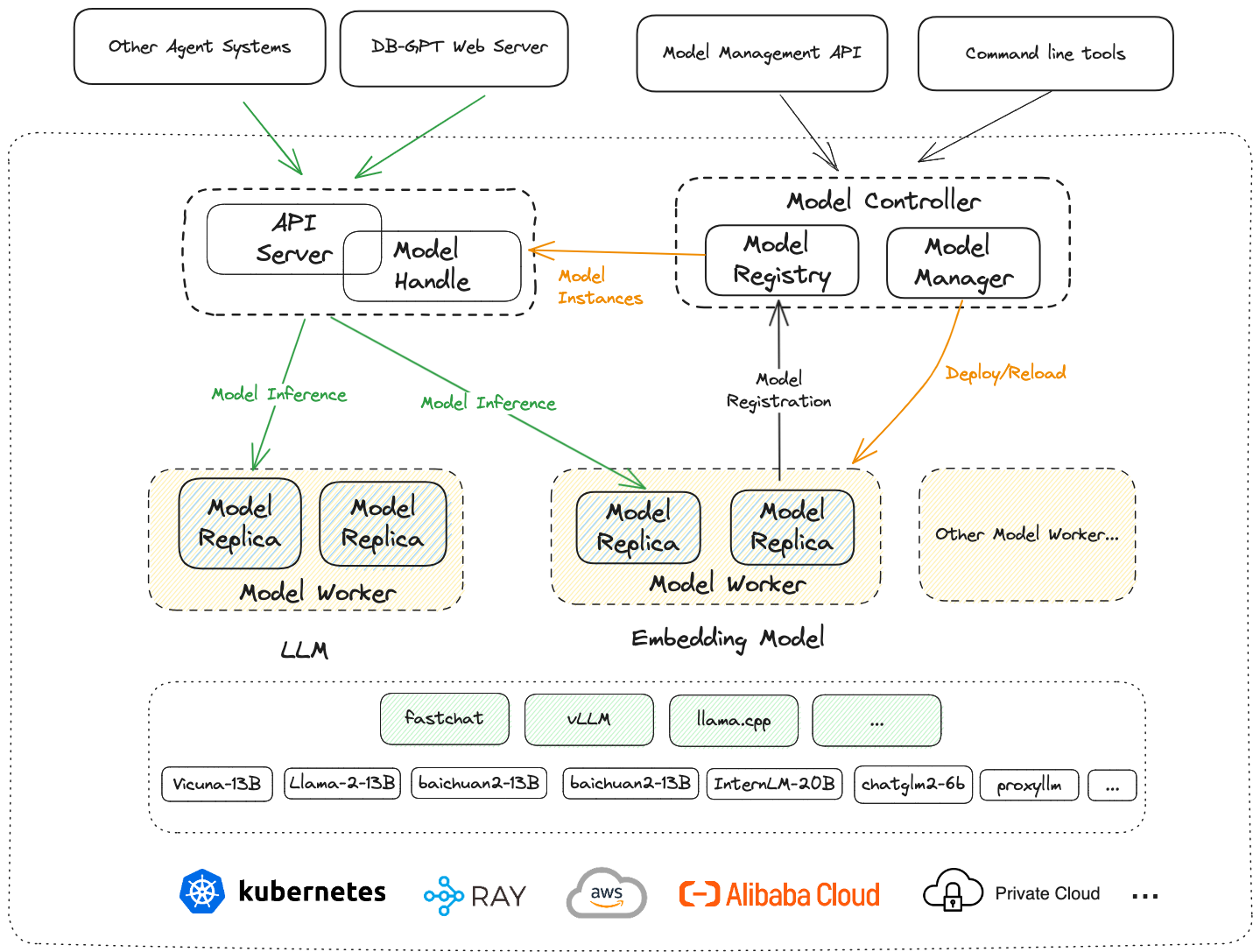
The model worker and API server can be deployed on different machines, and the model worker and API server can be deployed with multiple instances. But the model controller has only one instance by default, because it is a stateful service and stores all metadata of the model service, specifically, all metadata are stored in the component named Model Registry.
The default model registry is EmbeddedModelRegistry, which is a simple in-memory component.
To support high availability, we can use StorageModelRegistry as the model registry,
it can use a database as the storage backend, such as MySQL, SQLite, etc.
So we can deploy the model controller with multiple instances, and they can share the metadata by connecting to the same database.
Now let's see how to deploy the high availability cluster.
Deploy High Availability Cluster
For simplicity, we will deploy two model controllers on two machines(server1 and server2),
and deploy a model worker, an embedding model worker, and a web server on another machine(server3).
(Of course, you can deploy all of them on the same machine with different ports.)
Prepare A MySQL Database
- Install MySQL, create a database and a user for the model controller.
- Create a table for the model controller, you can use the following SQL script to create the table.
-- For deploy model cluster of DB-GPT(StorageModelRegistry)
CREATE TABLE IF NOT EXISTS `dbgpt_cluster_registry_instance` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Auto increment id',
`model_name` varchar(128) NOT NULL COMMENT 'Model name',
`host` varchar(128) NOT NULL COMMENT 'Host of the model',
`port` int(11) NOT NULL COMMENT 'Port of the model',
`weight` float DEFAULT 1.0 COMMENT 'Weight of the model',
`check_healthy` tinyint(1) DEFAULT 1 COMMENT 'Whether to check the health of the model',
`healthy` tinyint(1) DEFAULT 0 COMMENT 'Whether the model is healthy',
`enabled` tinyint(1) DEFAULT 1 COMMENT 'Whether the model is enabled',
`prompt_template` varchar(128) DEFAULT NULL COMMENT 'Prompt template for the model instance',
`last_heartbeat` datetime DEFAULT NULL COMMENT 'Last heartbeat time of the model instance',
`user_name` varchar(128) DEFAULT NULL COMMENT 'User name',
`sys_code` varchar(128) DEFAULT NULL COMMENT 'System code',
`gmt_created` datetime DEFAULT CURRENT_TIMESTAMP COMMENT 'Record creation time',
`gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Record update time',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_model_instance` (`model_name`, `host`, `port`, `sys_code`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='Cluster model instance table, for registering and managing model instances';
Start Model Controller With Storage Model Registry
We need to start the model controllers on two machines(server1 and server2), and
they will share the metadata by connecting to the same database.
- Start the model controller on
server1:
dbgpt start controller \
--port 8000 \
--registry_type database \
--registry_db_type mysql \
--registry_db_name dbgpt \
--registry_db_host 127.0.0.1 \
--registry_db_port 3306 \
--registry_db_user root \
--registry_db_password aa123456
- Start the model controller on
server2:
dbgpt start controller \
--port 8000 \
--registry_type database \
--registry_db_type mysql \
--registry_db_name dbgpt \
--registry_db_host 127.0.0.1 \
--registry_db_port 3306 \
--registry_db_user root \
--registry_db_password aa123456
Note: please modify the parameters according to your actual situation.
Start Model Worker
Start glm-4-9b-chat model Worker
dbgpt start worker --model_name glm-4-9b-chat \
--model_path /app/models/glm-4-9b-chat \
--port 8001 \
--controller_addr "http://server1:8000,http://server2:8000"
Here we use server1 and server2 as the controller address, so the model worker can
register to any healthy controller.
Start Embedding Model Worker
dbgpt start worker --model_name text2vec \
--model_path /app/models/text2vec-large-chinese \
--worker_type text2vec \
--port 8003 \
--controller_addr "http://server1:8000,http://server2:8000"
⚠️ Make sure to use your own model name and model path.
Deploy Web Server
LLM_MODEL=glm-4-9b-chat EMBEDDING_MODEL=text2vec \
dbgpt start webserver \
--light \
--remote_embedding \
--controller_addr "http://server1:8000,http://server2:8000"
Show Your Model Instances
CONTROLLER_ADDRESS="http://server1:8000,http://server2:8000" dbgpt model list
Congratulations! You have successfully deployed a high availability cluster of DB-GPT.
Deploy High Availability Cluster With Docker Compose
If your want know more about deploying a high availability DB-GPT cluster, you can see
the example of docker compose in docker/compose_examples/ha-cluster-docker-compose.yml.
It uses OpenAI LLM and OpenAI embedding model, so you can run it directly.
Here we will show you how to deploy a high availability cluster of DB-GPT with docker compose.
First, build the docker image just include openai dependencies:
bash ./docker/base/build_proxy_image.sh --pip-index-url https://pypi.tuna.tsinghua.edu.cn/simple
Then, run the following command to start the high availability cluster:
OPENAI_API_KEY="{your api key}" OPENAI_API_BASE="https://api.openai.com/v1" \
docker compose -f ha-cluster-docker-compose.yml up -d
QA
It will support more model registry types in the future?
Yes. We will support more model registry types in the future, such as etcd, consul, etc.
How to deploy the high availability cluster with Kubernetes?
We will provide a Helm chart to deploy the high availability cluster with Kubernetes in the future.